云南省图书馆机构用户,欢迎您!
认知建模近年来在科学心理学获得广泛应用,而模型比较是认知建模中关键的一环:研究者需要通过模型比较选择出最优模型,才能进行后续的假设检验或潜变量推断。模型比较不仅要考虑模型对数据的拟合(平衡过拟合与欠拟合),也需要考虑模型的复杂度。然而,模型比较指标众多,纷繁复杂,给研究者的选用带来困难。本文将认知建模常用的模型比较指标分为三大类并介绍其计算方法及优劣,包括拟合优度指标(包括均方误差、决定系数、ROC曲线等)、基于交叉验证的指标(包括AIC、DIC等)和基于边际似然的指标。结合正交Go/No-Go范式的公开数据,本文展示各指标在R语言中如何实现。在此基础上,本文探讨各指标的适用情境及模型平均等新思路。
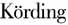 & Wolpert,2006)和漂移扩散模型(Drift diffusion model)(Forstmann et al.,2016;Ratcliff et al.,2016)等在认知神经科学得到广泛应用。类似地,强化学习模型(Reinforcement learning model)在价值决策(Value-based decision-making)研究中日益成为主流,其通过模型得到隐变量“预期误差(Prediction error)”可以有效地预测学习过程中多巴胺神经元(dopaminergic neuron)活动(Schultz et al.,1997;Steinberg et al.,2013)。计算模型也是计算精神病学(Computational psychiatry)这一新兴交叉领域的基础(Geng et al.,2022;Huys et al.,2016;Montague et al.,2012;区健新等,2020),增进理解精神疾病人群在认知加工上缺陷,以提高对精神疾病诊断和分类的准确度,提供精准治疗(Pedersen et al.,2021)。 认知模型的步骤大致包括模拟数据(Simulation)、参数估计(Parameter estimation)、模型比较(Model comparison)和隐变量推断(Latent variable inference)等步骤(Wilson & Collins,2019)。具体而言,研究者根据不同理论提出相应的计算模型,并设计实验收集数据,使用各个模型拟合数据,通过模型比较来选出最优模型,最后根据最优模型进一步分析数据,对模型的隐变量进行推断或进一步将隐变量与神经数据结合后进行解释。 模型比较是认知建模至关重要的一环,然而心理学/认知科学等领域研究者对模型比较的方法较为陌生,面对种类繁多的模型比较指标常感到困惑。此外,当前文献中也缺乏对模型比较的诸多方法进行系统梳理。鉴于此,本文梳理模型比较的原则和常见方法,以帮助读者理解当前模型比较各指标背后的原理和适用情境。尽管本文以认知建模作为切入点介绍模型比较的各指标,但是这些指标也可应用于其他涉及计算模型的场景中,例如分层线性回归、结构方程模型等。 本文将首先阐述模型比较的基本原则,接着系统性地介绍常用的模型比较指标,包括其原理、优点和局限性。随后结合实际数据示例,展示如何在R语言中应用这些指标。最后,对各项指标的优势和在使用过程的注意事项进行总结和讨论。 1 模型比较的基本原则 一个好的模型必须具备如下两点特质:第一,它能够很好地解释或者拟合当前样本数据的模型;第二,模型要具有较强泛化能力,即能够对于当前数据之外的数据同样提供较好的解释(即预测能力)。如果某个模型无法准确地解释当前样本数据,则可认为这个模型是欠拟合的(Underfitting)。如果某个模型能够非常好地解释当前样本数据但无法解释样本外的数据时,则认为这个模型过拟合的(Overfitting)(Friedman et al.,2001)。 研究者通常使用泛化误差(Generalization error),即模型预测和真实数据的差异来衡量模型的泛化能力。泛化误差可以被分为偏差(Bias)、方差(Variance)和误差项(Irreducible error)。偏差衡量的是模型预测的期望值与真实数据之间的偏差。偏差高的模型代表模型过于简单,无法有效捕捉到数据的信息,从而导致欠拟合。而方差衡量模型在不同训练数据集上的预测结果的变异程度。方差高的模型意味着模型过于复杂,学习到训练数据的随机噪声,从而导致过拟合。误差项是指数据本身所包含的不可减少的噪声和不确定性,任何模型都存在这部分误差。如图1所示,随着模型的复杂度的增大,模型的偏差会逐渐减小,方差则会增大,被称作偏差-方差权衡(Bias-variance trade-off)。因此,模型选择是一个权衡模型偏差和方差,从而使得其泛化误差最小的过程(Friedman et al.,2001)。
& Wolpert,2006)和漂移扩散模型(Drift diffusion model)(Forstmann et al.,2016;Ratcliff et al.,2016)等在认知神经科学得到广泛应用。类似地,强化学习模型(Reinforcement learning model)在价值决策(Value-based decision-making)研究中日益成为主流,其通过模型得到隐变量“预期误差(Prediction error)”可以有效地预测学习过程中多巴胺神经元(dopaminergic neuron)活动(Schultz et al.,1997;Steinberg et al.,2013)。计算模型也是计算精神病学(Computational psychiatry)这一新兴交叉领域的基础(Geng et al.,2022;Huys et al.,2016;Montague et al.,2012;区健新等,2020),增进理解精神疾病人群在认知加工上缺陷,以提高对精神疾病诊断和分类的准确度,提供精准治疗(Pedersen et al.,2021)。 认知模型的步骤大致包括模拟数据(Simulation)、参数估计(Parameter estimation)、模型比较(Model comparison)和隐变量推断(Latent variable inference)等步骤(Wilson & Collins,2019)。具体而言,研究者根据不同理论提出相应的计算模型,并设计实验收集数据,使用各个模型拟合数据,通过模型比较来选出最优模型,最后根据最优模型进一步分析数据,对模型的隐变量进行推断或进一步将隐变量与神经数据结合后进行解释。 模型比较是认知建模至关重要的一环,然而心理学/认知科学等领域研究者对模型比较的方法较为陌生,面对种类繁多的模型比较指标常感到困惑。此外,当前文献中也缺乏对模型比较的诸多方法进行系统梳理。鉴于此,本文梳理模型比较的原则和常见方法,以帮助读者理解当前模型比较各指标背后的原理和适用情境。尽管本文以认知建模作为切入点介绍模型比较的各指标,但是这些指标也可应用于其他涉及计算模型的场景中,例如分层线性回归、结构方程模型等。 本文将首先阐述模型比较的基本原则,接着系统性地介绍常用的模型比较指标,包括其原理、优点和局限性。随后结合实际数据示例,展示如何在R语言中应用这些指标。最后,对各项指标的优势和在使用过程的注意事项进行总结和讨论。 1 模型比较的基本原则 一个好的模型必须具备如下两点特质:第一,它能够很好地解释或者拟合当前样本数据的模型;第二,模型要具有较强泛化能力,即能够对于当前数据之外的数据同样提供较好的解释(即预测能力)。如果某个模型无法准确地解释当前样本数据,则可认为这个模型是欠拟合的(Underfitting)。如果某个模型能够非常好地解释当前样本数据但无法解释样本外的数据时,则认为这个模型过拟合的(Overfitting)(Friedman et al.,2001)。 研究者通常使用泛化误差(Generalization error),即模型预测和真实数据的差异来衡量模型的泛化能力。泛化误差可以被分为偏差(Bias)、方差(Variance)和误差项(Irreducible error)。偏差衡量的是模型预测的期望值与真实数据之间的偏差。偏差高的模型代表模型过于简单,无法有效捕捉到数据的信息,从而导致欠拟合。而方差衡量模型在不同训练数据集上的预测结果的变异程度。方差高的模型意味着模型过于复杂,学习到训练数据的随机噪声,从而导致过拟合。误差项是指数据本身所包含的不可减少的噪声和不确定性,任何模型都存在这部分误差。如图1所示,随着模型的复杂度的增大,模型的偏差会逐渐减小,方差则会增大,被称作偏差-方差权衡(Bias-variance trade-off)。因此,模型选择是一个权衡模型偏差和方差,从而使得其泛化误差最小的过程(Friedman et al.,2001)。 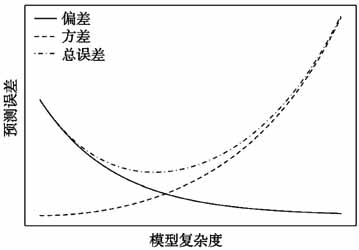 图1 偏差-方差权衡示意图 随着模型复杂度(Model complexity)的增加,偏差逐渐减小,方差逐渐增大。总的误差(Total error)有一个最小值。 模型复杂度对该模型泛化能力有着重要作用,诸多因素都会对模型复杂度有影响。Myung和Pitt(1997)总结三种常见影响模型复杂度的因素。第一是模型参数数量。一般情况下模型参数越多复杂度越高。第二是模型的数学形式。例如,非线性模型通常要比线性模型更复杂。第三是模型的参数空间范围。更大的参数空间范围说明模型拥有更多的自由度,也意味着模型更复杂。
图1 偏差-方差权衡示意图 随着模型复杂度(Model complexity)的增加,偏差逐渐减小,方差逐渐增大。总的误差(Total error)有一个最小值。 模型复杂度对该模型泛化能力有着重要作用,诸多因素都会对模型复杂度有影响。Myung和Pitt(1997)总结三种常见影响模型复杂度的因素。第一是模型参数数量。一般情况下模型参数越多复杂度越高。第二是模型的数学形式。例如,非线性模型通常要比线性模型更复杂。第三是模型的参数空间范围。更大的参数空间范围说明模型拥有更多的自由度,也意味着模型更复杂。