云南省图书馆机构用户,欢迎您!
随机森林模型是精准刻画区域人口分布规律和影响机制的主流研究方法。本文以石家庄为实验区,以综合禀赋分区为建模单元,在公顷网格粒度上分区开展分层采样,系统进行了递增式人口密度影响因子遴选实验,全流程(分区建模、分层采样、因子遴选、加权输出)优化了人口密度随机森林模型。研究表明:①分区建模抑制了模型混淆人口分布法则问题;在栅格粒度上采样,不仅使训练样本数据质量摆脱了MAUP的困扰,而且在形式上尝试降低区群谬误的不良影响;分层采样确保了样本数据集中人口密度标签值的分布稳定性。②利用人口密度随机森林模型,分区开展人口密度影响因子遴选实验,逐步提升了模型的拟合优度 ;距聚落距离是各区人口密度的主要影响因子;各区的人口分布影响机制存在显著差异,创新禀赋因子对城镇地区人口密度有较强影响,自然禀赋因子对乡村地区人口密度有较强影响。③对人口密度预测数据集进行优化组合,显著提高了模型的鲁棒性。④所获人口密度数据集具有多尺度叠加特征,大尺度上呈现出平原人口密度高于山区,小尺度上呈现出城镇人口密度高于乡村的“核心—边缘”特征。人口密度随机森林模型优化方案为揭示地方性人口分布规律和人口分布影响机制提供了统一的技术框架。
;距聚落距离是各区人口密度的主要影响因子;各区的人口分布影响机制存在显著差异,创新禀赋因子对城镇地区人口密度有较强影响,自然禀赋因子对乡村地区人口密度有较强影响。③对人口密度预测数据集进行优化组合,显著提高了模型的鲁棒性。④所获人口密度数据集具有多尺度叠加特征,大尺度上呈现出平原人口密度高于山区,小尺度上呈现出城镇人口密度高于乡村的“核心—边缘”特征。人口密度随机森林模型优化方案为揭示地方性人口分布规律和人口分布影响机制提供了统一的技术框架。
 。截至2020年11月1日,石家庄市常住人口为1123.51万人[41]。
。截至2020年11月1日,石家庄市常住人口为1123.51万人[41]。 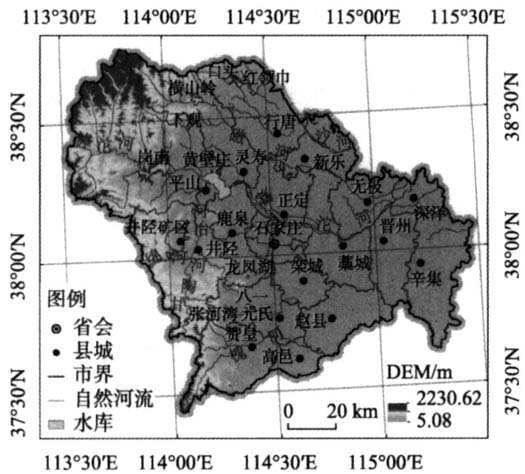 图1 研究区行政区划与地形 Fig.1 Administrative divisions and terrain of the study area 2.2 数据来源 文中所用主要数据集详见表1。村人口数据集为2007年4月30日24时石家庄市户籍人口分村统计数据,村界、聚落数据集取自第二次全国土地调查数据集,依托上述3个数据集,利用二元加权模型,计算获得聚落人口密度数据集,是文中建模所需的人口密度标签数据集。 文中从自然禀赋、经济禀赋和创新禀赋3个维度选取人口密度的候选影响因子。其中,自然禀赋因子包括海拔高度、地形起伏度、坡度、年均温、年均降水量、距河流距离(包括自然和人工河流)、距自然河流距离;经济禀赋因子包括距POIs距离、距聚落距离;创新禀赋因子包括POIs核密度、聚落核密度、夜光影像。上述数据集全部采用Albers伪圆锥等积投影。各栅格数据集均为GeoTiff格式,栅格尺寸统一为100m×100m,统一了各数据集的四至点坐标。
图1 研究区行政区划与地形 Fig.1 Administrative divisions and terrain of the study area 2.2 数据来源 文中所用主要数据集详见表1。村人口数据集为2007年4月30日24时石家庄市户籍人口分村统计数据,村界、聚落数据集取自第二次全国土地调查数据集,依托上述3个数据集,利用二元加权模型,计算获得聚落人口密度数据集,是文中建模所需的人口密度标签数据集。 文中从自然禀赋、经济禀赋和创新禀赋3个维度选取人口密度的候选影响因子。其中,自然禀赋因子包括海拔高度、地形起伏度、坡度、年均温、年均降水量、距河流距离(包括自然和人工河流)、距自然河流距离;经济禀赋因子包括距POIs距离、距聚落距离;创新禀赋因子包括POIs核密度、聚落核密度、夜光影像。上述数据集全部采用Albers伪圆锥等积投影。各栅格数据集均为GeoTiff格式,栅格尺寸统一为100m×100m,统一了各数据集的四至点坐标。