创新发展是“十三五”时期经济结构实现战略性调整的关键驱动因素,是实现“五位一体”总体布局下全面发展的根本支撑和关键动力。中国在“十四五”规划中再一次强调了创新的重要性。加快技术创新是推动经济高质量发展、提高人民生活品质、构建发展新格局以及建设现代化强国的动力。而物流业是中国经济社会发展的基础性、战略性和先导性产业,对国民经济发展意义重大,其高质量发展是经济高质量发展的强力推手。推进物流高质量发展有利于加快国民经济运行效率、助力经济增长、促进产业结构转型升级等。创新是物流高质量发展的内生动力,为了促进物流业高质量发展,就要发挥创新的引领作用。物流创新主要包括物流制度创新、物流管理创新、管理技术与方法创新以及物流技术创新4个方面。其中技术创新是核心,不仅可以降低物流成本和提高综合竞争力,而且对引导现代物流产业转型升级具有重大意义。因此了解物流业技术创新要素的现状、差异来源以及演变趋势对物流高质量发展具有深厚的理论意义和现实引导作用。 目前学术界对于创新的研究主要包括创新水平的测算、差异分析、创新的网络特征以及创新空间研究。对于创新水平的衡量方法,国外的文献更多的是采用专利被引用的次数[1]、存活期[2]、权项数[3]等来衡量创新水平;但由于国家知识产权局没有提供相关数据知识,国内学者都从侧面入手,利用知识宽度算法[4]、发明专利的申请数量[5.6]、专利更新模型[6]、DEA[7,8]、复相关系数[9]、超效率SBM模型[10]、知识生产函数[11]和多指标综合评价[12]等方法进行测算,采用区位熵[13]、变异系数[14]、赫芬达尔系数[15]、泰尔指数[7,16]和基尼系数[17]等分析创新能力的空间差异。对于创新网络特征的研究,大多学者利用专利数据结合社会网络分析法(SNA)[18,19]和复杂网络[20]来构建创新网络和对网络特征以及联系强度等进行研究。运用空间计量模型[21]和负二项回归[22]等方法分析其影响因素及驱动机制。现有文献对于物流业创新的研究主要集中在对创新网络的刻画。如孙春晓等[23]用社会网络分析方法探究中国城市物流网络的空间特征,采用空间杜宾模型来探究其驱动因素;宓泽锋和曾刚[24]通过SNA和负二项回归方法分析了长江经济带合作创新网络特征及其影响因素。准确识别中国各地区创新要素的时间变化趋势、空间分布情况以及动态演进过程有助于我国形成以自主创新为根本的国内大循环[25]。然而目前较少文献关注到物流产业创新要素的配置情况,测度物流业技术创新水平对于中国政府了解物流业技术创新水平现状、明确未来改进方向具有重大的现实意义。因此,本文以中国30个省(区、市)作为研究主体,利用爬虫技术获取到2001-2019年中国物流业的专利数据,运用Dagum基尼系数探究中国物流业技术创新水平的差异来源及大小;并采用高斯核密度函数探析中国物流业技术创新水平的演进趋势。正确把握地区物流业技术创新发展态势,助力经济健康循环发展。 1 研究方法与数据说明 1.1 研究方法 (l)Dagum基尼系数。Dagum基尼系数[18]是由Dagum在1997提出用来刻画地区发展不平衡问题的。其主要思想是按照子群来分解基尼系数。本文利用该方法衡量中国物流业技术创新的区域差异。结合该目标,本文建立如下的Dagum基尼系数计算公式,从省域层面刻画物流创新的区域差异。本文对公式进行了简化,具体的计算过程参照孙亚男等(2016)的研究[26]。
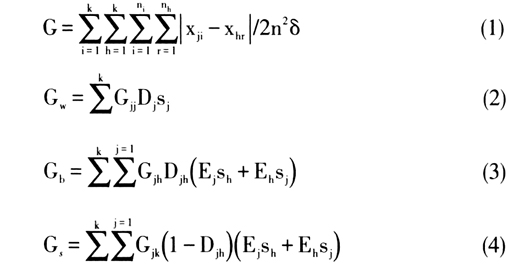

(2)核密度估计。核密度估计方法(非参数估计)是为改进参数估计的基本假定与实际模型之间存在差距较大的缺陷而提出的。常见的核函数包括均匀核、三角核以及高斯核等。本文采用高斯核函数对中国物流业技术创新水平的分布动态演进进行估计。其原理是通过核函数将每个数据点的数据和带宽当作核函数的参数,得到N个核函数,再线性叠加就形成了核密度的估计函数。假设随机变量x是中国物流业技术创新水平,其密度函数f(x),则点x处的概率密度为:
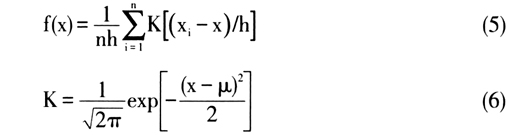
其中,n代表观测值的个数,h代表带宽,
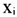
代表观测值,x表示物流业技术创新水平的平均值,函数K(*)为高斯核函数。 1.2 数据说明 本文数据来源于“国家重点产业专利信息服务平台”,该平台是国家知识产权局为配合国务院十大重点产业调整和振兴规划的实施,发挥专利信息对经济社会发展和企业创新活动的支撑作用而建立的。平台将物流产业划分为装卸搬运、物流运输、库存(仓储、保管)技术、流通加工、分拣包装配送系统以及物流信息技术6个细分领域。专利数据能更好的衡量创新的产出而不是创新的投入[27],所以本文利用发明专利申请量来表征物流业技术创新水平。