随着全球经济的不断发展与变化,投资在企业三大活动中所占的比例越来越高,成为企业中极其重要的活动。长期股权投资作为投资活动的重要类别,可分为对子公司的投资、对合营企业的投资和对联营企业的投资三类。根据会计准则要求、分类不同,适用的初始计量和后期核算方法都不一样。在此背景下,有些企业可能会钻空子,将投资分类为利好业绩的一类,达到调整报表业绩的目的,影响市场投资者的判断。因此,一个能对长期股权投资进行正确分类的工具,不论是对保证企业会计核算的准确性、提高审计的质量,抑或是增强监管机构的监督能力,都具有十分重要的意义。 目前,因构成股权投资的合同、协议等有大量的文字,对它们的分类只能依赖人工判断。而从审计工作和政府监管的需求来看,面对企业大量的长期股权投资,若仅采用人工分类,耗时长且效率低。为弥补人工分类的不足,本文尝试运用自然语言处理技术和机器学习方法,构建一个长期股权投资的分类模型,希望能通过此模型实现对股权投资的初步分类,在一定程度上实现股权投资分类的自动化和批量化。 二、长期股权投资 (一)股权投资定义 股权投资,又称权益性投资,是指投资方通过付出现金或其他资产获得被投资单位的股份,享有被投资单位的相关股东权利。股权投资形成投资方的金融资产、被投资单位的权益工具。根据投资之后投资方能够对被投资单位施加影响的程度,将其分为按照《企业会计准则第22号——金融工具确认和计量》进行核算和按照《企业会计准则第2号——长期股权投资》进行核算两类。本文研究的是长期股权投资的分类。 (二)长期股权投资的分类依据 根据投资方对被投资单位施加影响的程度,长期股权投资可以分为对联营企业投资、对合营企业投资和对子公司投资三类。 1.对联营企业投资 对联营企业投资,是指投资方能够对被投资单位施加重大影响的股权投资。对于重大影响的判定,企业会计准则没有给出具体的判断标准,只是将其定义为“投资方对被投资单位的财务和生产经营决策有参与决策的权力,但并不能够控制或者与其他方一起共同控制这些政策的制定”。会计准则应用指南中举例了以下情况来判断是否具有重大影响:在董事会或类似机构派有代表、发生重要交易、派有管理人员、提供关键技术材料等。 2.对合营企业投资 对合营企业投资,是指投资方持有的对构成合营企业的合营安排的投资。判断对合营企业的投资时,首先看是否构成合营安排,其次看有关合营安排是否构成合营企业。 3.对子公司投资 当投资方能够直接对被投资单位实施控制时,该投资即为对子公司的投资。控制,是指投资方拥有对被投资方的权力,通过参与被投资方的相关活动而享有可变回报,并且有能力运用对被投资方的权力影响其回报金额。会计准则中定义控制的三项基本要素为相关活动主导权、获利权和影响回报权。 基于以上会计准则的要求,在判断长期股权投资的类别时,最重要的是寻找关于权力来源、控股比例、董事会结构等方面的关键信息。 三、自然语言处理与机器学习方法 本文尝试实现长期股权投资的智能分类,是对文本类型的数据进行分类。因此,在构建模型前,我们需要先将数据进行自然语言处理,对文本进行分词,通过统计方法将文本数据转换为向量形式的数值型数据。在此基础上,我们再构建适合的机器学习分类模型对数据进行分类。 (一)文本分词技术 分词是将一段文本分割为词语,主要应用于自然语言处理,如进行关键词提取优化搜索、智能问答系统中语义分析等。英文中使用空格来分开每个单词,而中文词语和单个字之间的含义有时相差甚远,因此需要采用专门的中文分词来进行语句切割。本文的研究是基于Python语言进行代码编写,Python中有许多中文分词库,常见的有jieba、THULAC、pkuseg等。本文选用的是jieba分词。 jieba分词支持四种分词模式:精确模式、全模式、搜索引擎模式和paddle模式。除简单的分词模式外,jieba还支持繁体分词、自定义词典和词性标注等,是一个强大的中文开源分词包,拥有高性能与高准确率、可扩展等特点。 (二)TF-IDF统计方法 TF-IDF是用于评估字词对于一个文件集或一个语料库中的其中一份文件的重要程度的统计方法。TF-IDF统计方法的主要思想是:如果某个词语或短语在一篇文章中出现的频率很高,同时它在其他文章中很少出现,则认为此词语或短语具有很好的类别区分能力,适合用来分类。其实际上是TF(Term frequency,词频)*IDF(Inverse document frequency,逆文档频率)。 TF,词频,即某个词语在文档中出现的次数。出现频率越高的词语,TF值越大。TF的计算公式为:
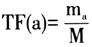
TF(a)表示词语a在一篇文档Di中出现的频率,
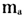
表示词语a在文档Di中出现的频数,M表示文档Di中所有的词语总数。