云南省图书馆机构用户,欢迎您!
根据5A级物流企业在我国各城市业务网点布局数据,建立了以城市为节点的物流运营网络,并利用复杂网络4个中心性指标,从联系广度和联系强度两个维度构建了城市对外物流联系能力评价体系。依据每个城市的4项指标值,用聚类分析的方法将城市节点分级,并计算了4项指标对分级的影响力,在此基础上提出基于区块划分和圈层划分的节点城市层级分析模型,据此揭示城市的发展方向和路径。最后,结合不同地区城市节点层级分布形态,分析了对各地区城市节点层级结构进行合理化调整的方向,并指出了各地区的潜力城市。
 中,有
中,有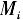 个企业在此布有网点,则记城市的“物流服务强度”为。物流服务强度越大的城市之间,物流联系强度越大;同时,城市间距离越大,物流联系强度越小。因此城市间物流联系强度
个企业在此布有网点,则记城市的“物流服务强度”为。物流服务强度越大的城市之间,物流联系强度越大;同时,城市间距离越大,物流联系强度越小。因此城市间物流联系强度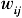 应与城市物流服务强度正相关,与城市间距离r负相关,符合引力模型的基本概念。因此,本文结合有关文献对城市间物流联系的分析方法[2-3],设其公式表达为:
应与城市物流服务强度正相关,与城市间距离r负相关,符合引力模型的基本概念。因此,本文结合有关文献对城市间物流联系的分析方法[2-3],设其公式表达为: 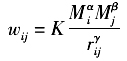 式中:α、β、γ为模型的指数常数;K为模型的比例系数;这里的距离r采用的是基于ArcGIS计算的城市交叉距离,单位为km。由于城市地理学中引力模型的模型参数可以根据具体条件计算乃至设置,只要使结果具有可比性就不会影响空间分析的整体效果[4],因此本文在选取参数时以保证数据具有合理的阈为原则,取α=β=1,K=0.01。其中,衰减参数γ具有分维性质,一般取1≤γ≤2[5],此处考虑到和
式中:α、β、γ为模型的指数常数;K为模型的比例系数;这里的距离r采用的是基于ArcGIS计算的城市交叉距离,单位为km。由于城市地理学中引力模型的模型参数可以根据具体条件计算乃至设置,只要使结果具有可比性就不会影响空间分析的整体效果[4],因此本文在选取参数时以保证数据具有合理的阈为原则,取α=β=1,K=0.01。其中,衰减参数γ具有分维性质,一般取1≤γ≤2[5],此处考虑到和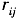 在值域上的差距和离散程度的合理性,取γ=1。以城市为节点,以物流联系强度为边权,可构建加权完备网络,此时网络中共19 306条边,边权值的分布阈∈[0,1900]。其中“权”为相似权,即权重越大,节点之间关系越紧密。 由于该网络属于完备网络,任意两节点间均有边相连,无法清晰直观地体现网络的拓扑性质。为了研究的可行性,需要剔除对网络结构贡献极小的边,将完备网络改造为以主要物流联系为边的骨干网络。如图1所示,权值最大的前5 000条边的权值之和占全部边权值之和的近90%,这说明仅少数边的权值较大,对网络结构形成关键影响;绝大多数边权值非常小,对网络结构贡献也较小。本文为权值设定阈值,取权值在阈值以上的边构建新网络[6]。在设定阈值时考虑两条原则:
在值域上的差距和离散程度的合理性,取γ=1。以城市为节点,以物流联系强度为边权,可构建加权完备网络,此时网络中共19 306条边,边权值的分布阈∈[0,1900]。其中“权”为相似权,即权重越大,节点之间关系越紧密。 由于该网络属于完备网络,任意两节点间均有边相连,无法清晰直观地体现网络的拓扑性质。为了研究的可行性,需要剔除对网络结构贡献极小的边,将完备网络改造为以主要物流联系为边的骨干网络。如图1所示,权值最大的前5 000条边的权值之和占全部边权值之和的近90%,这说明仅少数边的权值较大,对网络结构形成关键影响;绝大多数边权值非常小,对网络结构贡献也较小。本文为权值设定阈值,取权值在阈值以上的边构建新网络[6]。在设定阈值时考虑两条原则: