修订日期:2015-11-18 DOI:10.11821/dlyj201601006 1 引言 随着3S技术的发展,地理空间数据的内容日益丰富、来源越来越广泛、存储格式多样化。传统基于关键词的数据检索方式,很难满足用户需求。如“江苏省1∶10万土地利用数据”(A)与“无锡市1∶100万草地覆被数据”(B)两条数据,如果用户需要江苏省土地利用数据,通过关键字“江苏省”、“土地利用”等查询,只能查询到数据集A而不能查询到数据集B,但是,数据集B在空间上(无锡市)属于江苏省,在内容上(草地覆被)是土地利用的一种。因此,科研人员虽处于“信息的海洋”,却常面临“信息泛滥、知识匮乏”的困境[1]。在大数据环境下,如何准确快速地发现数据,成为地理空间数据共享应用面临的关键问题。关联数据的提出[2]为这一问题的解决提供了最佳实践。通过建立数据集A和数据集B之间的语义关联来实现数据的语义搜索。然而,仅仅依靠语义关联还不能够解决检索中的排序问题,因此还需要计算数据集之间的语义相关度。 语义相关度不仅包含词汇间的相似性,而且包括词汇之间根据各种语义关系具有的关联性[3],例如:对于“江苏省”和“无锡市”这两个词而言,虽然两者词汇相似性非常低,但其空间相关性却很高(无锡市属于江苏省)。除了空间关系,地理空间数据集之间还具有多种语义关系如属性类别关系、时间关系等。目前,国内外学者主要通过地理本体[4-7]、地名词典[8,9]、地理语义目录[10]等方式构建地理语义关系来辅助计算地理空间数据的语义相关性。然而,构建地理本体需要完整的概念体系和概念之间的空间关系,难度大、耗时长;地名词典、地理语义目录不能够表达地理空间特征的拓扑关系、度量关系等。因此,以地理空间元数据为语料库,选取用户检索中主要关注的空间、时间、内容三个特征,构建地理空间数据本质特征语义相关度计算模型。该模型通过建立空间、时间、内容三个维度的关联指标体系,并根据不同维度的语义特点,利用地理空间元数据提供的语义信息分别计算语义相关度,进而实现地理空间数据之间的语义关联,支持地理空间数据的精准搜索和排序。 2 地理空间数据本质特征语义关联指标体系 内容、空间、时间是多源地理空间数据的本质特征,每个特征的语义关联都是由多种语义关系构成的,这些语义关系在不同程度上影响地理空间数据的语义相关度。通过对本质特征的分析建立地理空间数据本质特征三级关联指标体系(表1)。每个指标的权重由专家打分确定。空间度量关系和时间度量关系如重叠比例、空间距离等,一方面可以辅助量化空间拓扑关系,另一方面可提高空间语义相关度计算的准确性。 (1)内容语义相关度,用Fsem表示,指地理空间数据集所表达的内容信息的相关程度。一部分取决于数据内容描述词汇的相似性,如土地覆被、土地利用的语义相似性很大;另一部分取决于内容所属的类别相关性,如果园与农用地词汇相似性非常低,但果园属于农用地,在类别上有一定的相关性。两部分分别用内容词汇语义相似度(F1)和类别相关度(F2)两个二级指标表示。 类别相关度包含类别层次相关度和类别相关比例两个三级指标。类别层次相关度是指在同一分类体系中,两个数据所属类别的相关程度。在某些情况下,同一地理空间数据集会同时属于多个类别,如“杭嘉湖地区1∶10万土地利用、水资源与水利工程(2000年)”数据集既属于土地资源类,又属于水资源类。因此,应用类别相关比例这一指标来度量多类别数据集之间的相关度。 (2)空间语义相关度,用Ssem表示,指地理空间数据所表达的空间实体间的空间关联程度,包括拓扑关系、度量关系和方位关系。方位关系在检索排序中的影响较小,采用拓扑关系和度量关系计算空间语义相关度。 空间拓扑关系主要包括相交、包含、相接等。同一拓扑关系,如包含关系,多个空间对象的距离、面积不同,其语义相关度也不同。如图1所示的面—面之间的拓扑关系,如采用空间实体几何中心的欧式距离,B同时包含A、C、D,距离(CB)=距离(AB)、面积(A)>面积(C),一般认为空间相关度(AB)>空间相关度(CB);距离(DB)>距离(CB)、面积(D)=面积(C),根据地理学第一定律[11]距离越近的两个事物相关性越紧密,则空间相关度(CB)>空间相关度(DB)。因此,空间语义关系在考虑空间拓扑关系的基础上,应进一步考虑空间重叠比例和空间距离等度量关系。

(3)时间语义相关度,用Tsem表示,指地理空间数据所表达时间(对于监测类的数据,可用采集时间代替)的关联程度。与空间语义相关度相似,时间语义相关度包括时间拓扑关系(
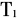
)和时间度量关系(
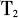
)两个二级指标。时间度量关系由时间重叠比例和时间距离构成。