云南省图书馆机构用户,欢迎您!
中国物流业碳排放总体地区差距呈下降趋势,2006年后呈缓慢上升趋势,其中,地区间净差距是总体差距的主要来源,其次为超变密度,地区内差距的贡献最小。物流碳排放的极化测度结果表明,中国物流碳排放分布的极化程度呈下降趋势。地区内的集聚程度和地区间的对抗程度不断减弱,最终成为碳排放极化程度下降的主要来源。一方面,各地区物流业碳排放水平的不断上升说明目前中国物流业仍处于粗放式增长,在物流产值和周转量增加的同时,忽视了碳排放这一必然副产品也随之增加的事实,这一现实提醒我们有必要根据自身物流业所处的发展阶段制定相应的碳减排措施;另一方面,中央及各地方政府在制定物流发展规划和相应的碳减排措施时,要充分考虑到中国各地区物流业发展的实际情况和地域特征,制定差异化的策略,使物流业碳减排和稳定发展相协调。

 对比Mookherjee和Shorrocks给出的基尼系数组群分解的表达式:
对比Mookherjee和Shorrocks给出的基尼系数组群分解的表达式:  上式右边第一项和第二项分别为地区内差距和地区间差距,为剩余项,反映地区间碳排放强度分布的交错程度。洪兴建指出式(10)、(11)各项在数量上分别相等[12],因此,(10)中第三项为剩余项的另一种诠释。 (二)区域空间极化的测度 极化是区域经济发展中出现的一种“中间阶层消失”的现象,本文利用极化指数衡量碳排放较多的东部地区和碳排放较低的中西部地区围绕各自所在区域均值聚集分布的不均衡状态。如果不同区域之间不均衡很大,同一区域内部不均衡较小,则认为存在空间极化现象。极化指数越大,极化现象越明显。本文测度了以下四种极化指数。 1.ER指数。在判断极化时,Esteban和Ray提出分布应具备三个特征:组内高度同质性、组间高度异质性、存在少量规模显著的组群,并通过定义组内认同感和组间疏远感对前两个特征进行度量。[13]ER指数用公式表示为:
上式右边第一项和第二项分别为地区内差距和地区间差距,为剩余项,反映地区间碳排放强度分布的交错程度。洪兴建指出式(10)、(11)各项在数量上分别相等[12],因此,(10)中第三项为剩余项的另一种诠释。 (二)区域空间极化的测度 极化是区域经济发展中出现的一种“中间阶层消失”的现象,本文利用极化指数衡量碳排放较多的东部地区和碳排放较低的中西部地区围绕各自所在区域均值聚集分布的不均衡状态。如果不同区域之间不均衡很大,同一区域内部不均衡较小,则认为存在空间极化现象。极化指数越大,极化现象越明显。本文测度了以下四种极化指数。 1.ER指数。在判断极化时,Esteban和Ray提出分布应具备三个特征:组内高度同质性、组间高度异质性、存在少量规模显著的组群,并通过定义组内认同感和组间疏远感对前两个特征进行度量。[13]ER指数用公式表示为: 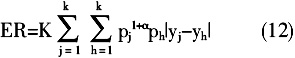 k为地区数,
k为地区数, 为j(h)组样本数占总体样本数的比重,
为j(h)组样本数占总体样本数的比重,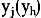 为j(h)组的平均碳排放水平,
为j(h)组的平均碳排放水平, 为认同函数,
为认同函数,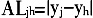 为疏远函数。K>0是起标准化作用的常数,假定K=10/u,u为所有地区物流业碳排放水平的均值,α是极化敏感度系数,α∈[1,1.6]。当α=0且K=0.5时,ER指数等同于基尼系数,本文取α=1.5。
为疏远函数。K>0是起标准化作用的常数,假定K=10/u,u为所有地区物流业碳排放水平的均值,α是极化敏感度系数,α∈[1,1.6]。当α=0且K=0.5时,ER指数等同于基尼系数,本文取α=1.5。