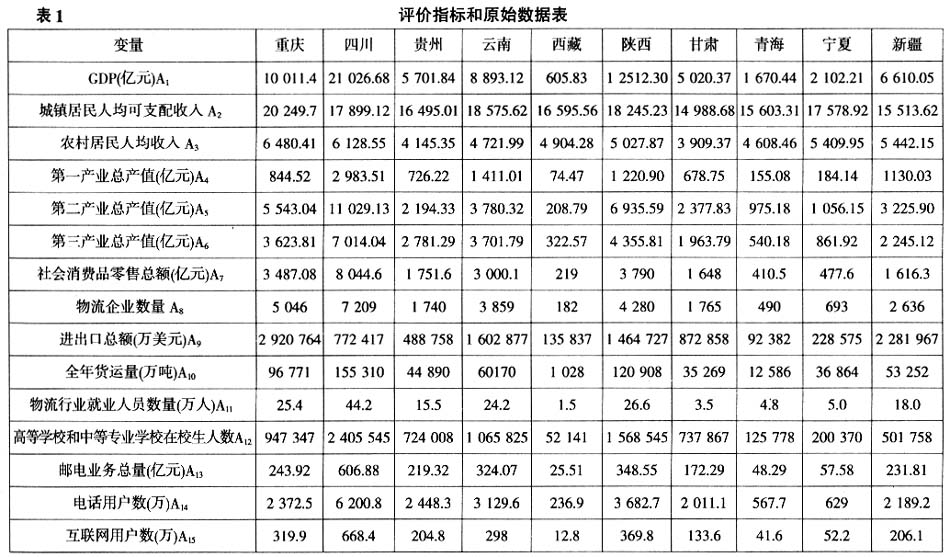
在经济发展过程中,实现各省(市)区物流业平稳较快增长,在保障该省(市)区生产良性运行、保障经济稳步发展等方面发挥着重要的支撑和服务作用。一般来说,物流综合实力越强,意味着该省(市)区的物流业增长就越平稳越快,从而该地区经济发展水平就越高、竞争力就越强。自2009年3月物流业被国务院发布的《物流业调整与振兴规划》正式列入调整与振兴的十大支柱产业之后,中国各地方政府都根据本地区物流业运行的特点和存在的主要问题,制订了物流建设的发展目标与规划,以期推进该地区国民经济和社会保持持续发展的态势,因此西部各省(市)区已制定相关策略以加强该地区物流业的发展。但是,要想制订出有针对性的西部各省(市)区物流发展的建设目标和策略,必须使用科学的方法,对西部各省(市)区的物流发展的实力给出客观、全面的综合评价。目前,对物流实力综合评价的研究已有很多,且取得了一些有意义的研究结果[1-3]。例如:李玉民等在文中提出把层次分析法和熵权法相结合确定各评价指标的权重,最后利用评价矩阵对各评价对象进行排序[1]。这种方法的不足之处是不能给出处理以后的数据包含了多少原始数据的信息,而且层次分析法中给出的随机一致性检验指标R的值是层次分析法的创始人T.L.Saaty通过实验根据经验得到的,没有做理论证明。王新安等在文中利用主成分因子分析法和聚类分析法,通过公因子排名和命名,对陕西省物流发展做了综合评价并指出了影响物流发展的主要因素[2],但是至今没有见到针对西部地区物流实力进行综合评价的实证研究。值得一提的是,传统的主成分因子分析法采用标准化方法处理原始数据,使得处理过后的数据方差都是1,从而丢掉了原始数据指标之间的偏离程度差异的信息,因此需要对主成分分析法进行改进。本文运用改进的主成分分析法,以与物流业发展密切相关的15个指标作为西部十省(市)区的物流实力综合评价的原始指标,对西部十省(市)区的物流实力做科学全面的综合评价,以期为决策提供有力的参考依据。 二、评价指标体系的构建 物流是物品从供应地向接受地的实体流动过程,根据实际需要,将运输、储存、装卸、搬运、包装、流通加工配送、信息处理等基本功能实施有机结合。因此,一个地区的物流发展水平主要由该地区社会经济基础、生产消费与流通、交通运输、人力资源和信息发展水平决定。为了使构建的区域物流评价指标体系既全面又客观,应从上述五方面出发,同时遵循评价指标选取的完整性、可获取性、科学性、可靠性原则。林璐龙在文中把上述五方面作为区域物流发展实力评价的一级指标,并在此基础上又细分为20项二级指标,具体如下:(1)社会经济发展类指标,包括:GDP、人均GDP、城镇居民人均收入、农村居民人均收入;(2)生产消费流通类指标,包括:工业人均总产值、建筑业人均总产值、人均社会消费零售额、产品销售收入、进出口总额;(3)交通运输类指标,包括:全社会货运量、客运总量、公路通车里程、邮路单程长度、公路分布密度;(4)人力资源类指标,包括:交通运输、仓储及邮政业从业人员数量、每万人拥有高等学校在校人数;(5)信息发展类指标,包括:邮政业务收入、电信业务收入、本地人均固定电话用户数、人均互联网用户数[4]。本文对上述20个二级指标做了一些改动,主要理由是:(1)考虑到人均GDP与GDP线性重叠性过高,因此在它们两个中只选取了GDP,用城镇居民人均可支配收入代替城镇居民人均收入显然更合理;(2)用第一产业总产值、第二产业总产值、第三产业总产值、社会消费品零售总额代替工业人均总产值、建筑业人均总产值、人均社会消费零售额、产品销售收入,弥补了缺乏农业总产值方面的信息,而农业物流在西部地区区域物流中占有很重要的地位;(3)客运总量与区域物流发展水平相关性太小,因此没有采用这个指标;全社会货运量和物流企业数量体现了地区的物流供给能力,一般来说,这两个指标越大,表明地区物流发展的硬件基础设施就越好,物流发展的竞争力和潜力就越大;(4)用邮电业务总量代替邮政业务收入和电信业务收入,使得指标体系更简洁。基于上述考虑,本文选取表1中的15个指标建立西部十省(市)区物流实力评价指标体系。 三、数据来源 为了使10个评价对象在每个指标变量上的取值具有权威性,且所做评价的结果具有时效性,本文各项指标采用的原始数据来自《中国物流年鉴(2011)》和《中国统计年鉴(2012)》,详见表1。
四、分析过程与结果 (一)主成分分析法的基本思想[5]279-281 当人们研究受多个因素综合影响的复杂问题时,为了不遗漏所研究问题包含的重要信息,一般情况下人们会选取众多与问题有关的指标变量。显然指标变量越多,包含的所研究问题的信息就越全面、详细,但是由于变量数目越多处理起来越困难,最终给问题的研究带来不便,因此需要研究如何通过少量的几个原始变量的线性组合(主成分)来代替众多具有一定相关性的原始变量,使它们尽可能多地包含原始变量的信息,且彼此不相关。这样原始变量间的信息重叠问题不仅得到了解决,而且大大降低了变量的维数,这就是主成分分析法的基本原理。其优点是少量的几个主成分包含的原始变量信息的百分比可以很容易计算出来,同时主成分之间的权重是由原始数据本身所决定,不受任何主观因素的影响,且主成分之间彼此不相关,避免了信息之间的相互交叉,保证了分析评价结果的可信性、全面性和客观性。 (二)改进的主成分分析法 传统的主成分分析法对原始指标变量进行标准化处理时采用的是z-score公式,其目的是为了消除原始指标不同量纲和数量级对协方差的影响。用这种方式处理后的指标变量方差相等全是1,这意味着处理后的指标变量之间没有了偏离程度的差异。由于主成分是标准化后指标变量的线性组合,因此主成分实际上只包含了原始变量的部分信息。可见,对传统主成分分析方法中原始数据无量纲化处理的算法进行改进是非常有必要的,指标均值法就是一种较好的改进方法,它不但消除了原始变量之间的量纲不同和数量级的差别,而且保持了原始变量的相关系数矩阵不变,同时原始变量的方差是处理后变量的方差的常数倍,即保留了原始变量的变异程度的差异,弥补了传统的主成分分析法的不足。下面是改进的主成分分析法的步骤:

