云南省图书馆机构用户,欢迎您!
社会物流总额与经济发展水平具有高度相关性,准确描述物流发展对经济的影响,建立面板数据模型,从区域层面定量说明物流对区域经济发展的作用和东中西部物流发展水平对经济发展影响逐渐减弱,以及区域物流发展水平的不平衡原因即基础设施、自然环境和经济发展等。加大各区域的物流基础设施建设,加强各省市的物流信息化建设,努力做好各省市的物流规划,以政府扶持为主,改革区域物流体系的管理体制等途径发展区域物流,进而促进经济发展。
 这些数据表明,随着国家经济的发展和物流业的逐渐发展完善,物流业对我国经济的稳定协调发展发挥着重要作用。物流业在服务贸易领域中占有举足轻重的地位,它连接社会经济的各个部分,已成为国民经济发展的基础产业。社会经济发展越来越依赖于现代物流业的支撑。在国际上,现代物流业被认为是国民经济发展的动脉和基础产业,其发展水平已成为衡量一个国家和地区现代化程度和综合竞争力的重要标志之一,被喻为继降低物质消耗、提高劳动生产率以外的“第三利润源泉”和促进经济发展的“加速器”[1]。本文正是建立在此观点基础上,为准确描述物流发展对经济的影响,按照区域划分,研究物流发展水平对区域经济发展的影响,以从区域层面定量说明物流对经济发展的作用。 二、实证模型分析 (一)数据指标选择 选择货物周转量、旅客周转量、批发零售贸易总额三个指标,将其对数化后再进行汇总整理,作为衡量物流发展水平指标。国内生产总值(GDP)作为经济发展水平指标,固定资产投资量作为资本存量的简单代替,就业人数作为劳动人数指标。以上各指标数据均以1978年为基年进行折算,以扣除价格因素影响。 东中西区域划分标准说明:西部地区包括的省级行政区共12个,分别是四川、重庆、贵州、云南、西藏、陕西、甘肃、青海、宁夏、新疆、广西、内蒙古;中部地区有8个省级行政区,分别是山西、吉林、黑龙江、安徽、江西、河南、湖北、湖南;东部地区包括北京、天津、河北、辽宁、上海、江苏、浙江、福建、山东、广东和海南等11个省(市)。由于重庆是在1997年以后才被划归为直辖市,本文将重庆市并入到四川省一同进行分析,由于是区域分析,这并不影响分析结果。西藏的部分数据缺失不全,因此分析时将西藏排除未予分析[2]。 利用1998-2007年各省市的上述数据指标进行汇总整理,建立横截面和时间序列数据即面板数据(Panel Data)计量模型,并利用Eviews计量软件进行求解分析。 (二)具体模型及求解结果分析 在柯布—道格拉斯生产函数形式的基础上,建立包含物流因素的对数线性形式生产函数[3]:
这些数据表明,随着国家经济的发展和物流业的逐渐发展完善,物流业对我国经济的稳定协调发展发挥着重要作用。物流业在服务贸易领域中占有举足轻重的地位,它连接社会经济的各个部分,已成为国民经济发展的基础产业。社会经济发展越来越依赖于现代物流业的支撑。在国际上,现代物流业被认为是国民经济发展的动脉和基础产业,其发展水平已成为衡量一个国家和地区现代化程度和综合竞争力的重要标志之一,被喻为继降低物质消耗、提高劳动生产率以外的“第三利润源泉”和促进经济发展的“加速器”[1]。本文正是建立在此观点基础上,为准确描述物流发展对经济的影响,按照区域划分,研究物流发展水平对区域经济发展的影响,以从区域层面定量说明物流对经济发展的作用。 二、实证模型分析 (一)数据指标选择 选择货物周转量、旅客周转量、批发零售贸易总额三个指标,将其对数化后再进行汇总整理,作为衡量物流发展水平指标。国内生产总值(GDP)作为经济发展水平指标,固定资产投资量作为资本存量的简单代替,就业人数作为劳动人数指标。以上各指标数据均以1978年为基年进行折算,以扣除价格因素影响。 东中西区域划分标准说明:西部地区包括的省级行政区共12个,分别是四川、重庆、贵州、云南、西藏、陕西、甘肃、青海、宁夏、新疆、广西、内蒙古;中部地区有8个省级行政区,分别是山西、吉林、黑龙江、安徽、江西、河南、湖北、湖南;东部地区包括北京、天津、河北、辽宁、上海、江苏、浙江、福建、山东、广东和海南等11个省(市)。由于重庆是在1997年以后才被划归为直辖市,本文将重庆市并入到四川省一同进行分析,由于是区域分析,这并不影响分析结果。西藏的部分数据缺失不全,因此分析时将西藏排除未予分析[2]。 利用1998-2007年各省市的上述数据指标进行汇总整理,建立横截面和时间序列数据即面板数据(Panel Data)计量模型,并利用Eviews计量软件进行求解分析。 (二)具体模型及求解结果分析 在柯布—道格拉斯生产函数形式的基础上,建立包含物流因素的对数线性形式生产函数[3]:  由于Panel Data含有横截面、时间和指标三维信息,利用该类数据可以构造和检验比以往单独使用横截面数据或时间序列数据更为真实的行为方程,可以进行更加深入的分析。正是基于实际经济分析的需要,作为非经典计量经济学问题,同时利用横截面和时间序列数据的模型,已经成为近年来计量经济学理论方法的重要发展之一。本文分析物流发展水平对区域经济发展的影响,更适于采用横截面和时间序列数据。 但由于既含有个体成员截面方程,又含有时间方程两种形式的模型,根据截距项向量和系数向量中各分量的不同限制要求,又可以将Panel Data模型分为三种类型[4]:无个体影响的不变系数模型、含有个体影响的变系数模型和变截距模型。如果模型形式设定不正确,估计结果将与所要模拟的经济现实偏离甚远。因此,建立Panel Data模型的第一步就是检验应采取上述三种模型的哪一种。经常使用的检验是协方差分析检验,主要检验如下两个假设:
由于Panel Data含有横截面、时间和指标三维信息,利用该类数据可以构造和检验比以往单独使用横截面数据或时间序列数据更为真实的行为方程,可以进行更加深入的分析。正是基于实际经济分析的需要,作为非经典计量经济学问题,同时利用横截面和时间序列数据的模型,已经成为近年来计量经济学理论方法的重要发展之一。本文分析物流发展水平对区域经济发展的影响,更适于采用横截面和时间序列数据。 但由于既含有个体成员截面方程,又含有时间方程两种形式的模型,根据截距项向量和系数向量中各分量的不同限制要求,又可以将Panel Data模型分为三种类型[4]:无个体影响的不变系数模型、含有个体影响的变系数模型和变截距模型。如果模型形式设定不正确,估计结果将与所要模拟的经济现实偏离甚远。因此,建立Panel Data模型的第一步就是检验应采取上述三种模型的哪一种。经常使用的检验是协方差分析检验,主要检验如下两个假设: 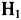 :各变量前系数都相等
:各变量前系数都相等 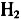 :各变量前系数都相等;且各截距都相等
:各变量前系数都相等;且各截距都相等