云南省图书馆机构用户,欢迎您!
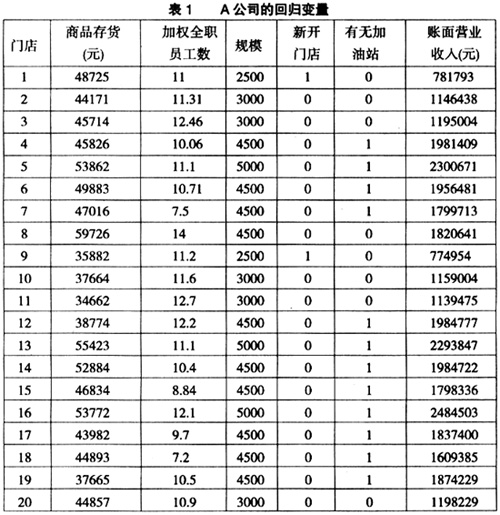 以Excel2003来说明回归过程。审计师首先将数据输入Excel工作簿,然后对数据进行回归运算。该运算包括五个步骤:第一步,点击“工具”菜单,选择“加载宏”;第二步,从“加载宏”的菜单中,选择“分析工具库”;第三步,再次点击“工具”菜单,此时下拉式菜单中会增加一项“数据分析”,点击该项;第四步,在弹出的界面中选择“回归”;第五步,在弹出的窗口中有“输入”、“输出选项”、“残差”和“正态分布”四个大项。“输入”项目中,在“Y值输入区域”输入对因变量营业收入数据区域的引用。该区域必须由单列数据组成。在“X值输入区域”输入对预测自变量数据区域的引用。自变量的个数最多为16。“输出区域”项中,输入对输出表左上角单元格的引用。 上述前两步的目的是安装回归分析的工具。汇总输出表包括:方差分析表、系数、Y估计值的标准误差、R平方值、观察值个数以及系数的标准误差。将回归结果简化为表2。
以Excel2003来说明回归过程。审计师首先将数据输入Excel工作簿,然后对数据进行回归运算。该运算包括五个步骤:第一步,点击“工具”菜单,选择“加载宏”;第二步,从“加载宏”的菜单中,选择“分析工具库”;第三步,再次点击“工具”菜单,此时下拉式菜单中会增加一项“数据分析”,点击该项;第四步,在弹出的界面中选择“回归”;第五步,在弹出的窗口中有“输入”、“输出选项”、“残差”和“正态分布”四个大项。“输入”项目中,在“Y值输入区域”输入对因变量营业收入数据区域的引用。该区域必须由单列数据组成。在“X值输入区域”输入对预测自变量数据区域的引用。自变量的个数最多为16。“输出区域”项中,输入对输出表左上角单元格的引用。 上述前两步的目的是安装回归分析的工具。汇总输出表包括:方差分析表、系数、Y估计值的标准误差、R平方值、观察值个数以及系数的标准误差。将回归结果简化为表2。 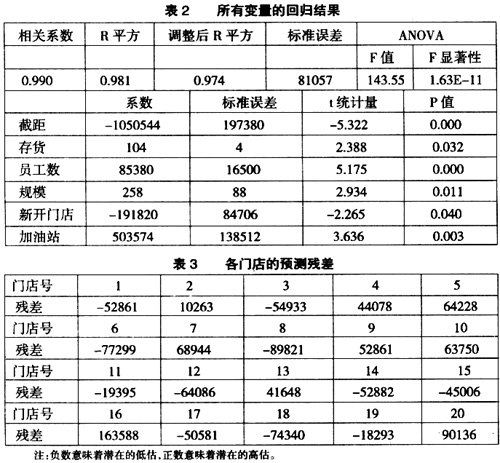 在表2中,97.4%水平的“调整后R平方”表明回归方程拟合效果很好,81057的标准误差也很好,它小于因变量平均值的5%。各个变量的t统计量都至少在5%的水平上显著。各个变量的系数符号方向也与预期相同。这说明,除了“新开门店”外,其他变量都与因变量正相关:当自变量增大时,自变量预期也应增大。相反,新开门店的负号系数则表明其营业收入将会更低。81057的标准误差小于计划的重要性水平150000元,为回归方程的使用提供了一定的可信度。相反,如果标准误差大于重要性水平,审计师应降低对回归方程的信赖。此外,如果某些预测变量t统计量不显著,审计师也可以剔除该变量。 综上所述,审计师可以认为表2所示的回归方程是有用的。因此,营业收入的期望值可以利用表2“系数”栏所示的自变量和相应系数得到。对A公司,各门店营业收入期望值的回归模型如下:营业收入=-1050544+104×存货+85380×员工数+258×规模-191820×新开门店+503574×加油站。 例如,2号门店营业收入的期望值就可以根据上述方式推导出来:营业收入=-1050544+104×44171+85380×11.31+258×3000-191820×0+503574×0=1136175。回归预测值与实际值1146438相比,差额为10263。该差异衡量了2号店与其他门店的偏离程度。对于各门店营业收入的回归预期值与实际值的差额,审计师可以直接通过在回归弹出窗口中选中“残差”选项后得出表3。 由于本例是要找出高估收入的地点,所以正的残差很重要。残差为正,表示账面未审计数比回归预测数高,存在高估收入的可能性。假设考虑风险和成本等因素后,审计师决定本年度审计中将选出六个门店进一步审计,则根据表3,显示正残差值较大的从高到低依次是16、20、7、5、10和9号店。进一步的调查应从这六个店开始,因为回归显示在考虑五个自变量数据关系的基础上,这些店与其他店相比最为异常。
在表2中,97.4%水平的“调整后R平方”表明回归方程拟合效果很好,81057的标准误差也很好,它小于因变量平均值的5%。各个变量的t统计量都至少在5%的水平上显著。各个变量的系数符号方向也与预期相同。这说明,除了“新开门店”外,其他变量都与因变量正相关:当自变量增大时,自变量预期也应增大。相反,新开门店的负号系数则表明其营业收入将会更低。81057的标准误差小于计划的重要性水平150000元,为回归方程的使用提供了一定的可信度。相反,如果标准误差大于重要性水平,审计师应降低对回归方程的信赖。此外,如果某些预测变量t统计量不显著,审计师也可以剔除该变量。 综上所述,审计师可以认为表2所示的回归方程是有用的。因此,营业收入的期望值可以利用表2“系数”栏所示的自变量和相应系数得到。对A公司,各门店营业收入期望值的回归模型如下:营业收入=-1050544+104×存货+85380×员工数+258×规模-191820×新开门店+503574×加油站。 例如,2号门店营业收入的期望值就可以根据上述方式推导出来:营业收入=-1050544+104×44171+85380×11.31+258×3000-191820×0+503574×0=1136175。回归预测值与实际值1146438相比,差额为10263。该差异衡量了2号店与其他门店的偏离程度。对于各门店营业收入的回归预期值与实际值的差额,审计师可以直接通过在回归弹出窗口中选中“残差”选项后得出表3。 由于本例是要找出高估收入的地点,所以正的残差很重要。残差为正,表示账面未审计数比回归预测数高,存在高估收入的可能性。假设考虑风险和成本等因素后,审计师决定本年度审计中将选出六个门店进一步审计,则根据表3,显示正残差值较大的从高到低依次是16、20、7、5、10和9号店。进一步的调查应从这六个店开始,因为回归显示在考虑五个自变量数据关系的基础上,这些店与其他店相比最为异常。