云南省图书馆机构用户,欢迎您!
鉴于传统绩效评价方法的局限性,采用数据包络分析法(DEA)对我国17家物流上市公司2004-2007年间的数据,进行绩效实证分析,并根据评价分析结果存在的问题,提出切实可行的对策建议。
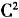 R模型和G
R模型和G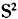 模型研究2002-2005年间中国物流上市公司绩效。这种方法可以评价不同量纲指标,不需要主观地赋予指标的相对权重,具有较强客观性。 参数法的特点是考虑了由于统计、观测等因素引起的误差,但其假设的边界函数具有一定的主观性,故评价结果不很精确。另外参数化法和非参数法一样,存在着指标选取的随意性问题。 本文试图构建基于财务指标的绩效评价指标体系,运用DEA方法R模型和G模型,分析和评价2004-2007年间我国17家上市物流企业绩效,比较港口类和运输类企业绩效的差异,并提出对策建议。 2 DEA模型建立及分析评价 2.1 模型的建立 DEA(数据包络分析)是运筹学、管理学和数理经济学交叉研究的一个新领域。它是由著名运筹学家A.Charnes和W.W.Cooper[8]等人以“相对效率”概念发展起来的一种崭新的效率评估方法。DEA是使用数学规划模型评价具有多个输入和多个输出的“部门”和“单位”(或称决策单元,简记为DMU)间的相对有效性(称为DEA有效)。根据对各DMU观察的数据判断DMU是否为DEA有效,本质上是判断DMU是否位于生产可能集的“前沿面”上。使用DEA对DMU进行效率评价时,可以得到很多在经济学中具有深刻经济含义和背景的管理信息。DEA评价模型特别适用于具有多个输入变量和输出变量的复杂系统,它对决策单元的规模有效性和技术有效性同时进行评价。 当今最具代表性的“经典”DEA模型有:R模型,B模型、FG模型和ST模型。这四个DEA模型之下的(弱)DEA有效性具有各自的经济含义。本文选用C2R模型和G模型,前者可用于评价决策单元的总体有效性,而后者可用于评价决策单元的纯技术有效性。
模型研究2002-2005年间中国物流上市公司绩效。这种方法可以评价不同量纲指标,不需要主观地赋予指标的相对权重,具有较强客观性。 参数法的特点是考虑了由于统计、观测等因素引起的误差,但其假设的边界函数具有一定的主观性,故评价结果不很精确。另外参数化法和非参数法一样,存在着指标选取的随意性问题。 本文试图构建基于财务指标的绩效评价指标体系,运用DEA方法R模型和G模型,分析和评价2004-2007年间我国17家上市物流企业绩效,比较港口类和运输类企业绩效的差异,并提出对策建议。 2 DEA模型建立及分析评价 2.1 模型的建立 DEA(数据包络分析)是运筹学、管理学和数理经济学交叉研究的一个新领域。它是由著名运筹学家A.Charnes和W.W.Cooper[8]等人以“相对效率”概念发展起来的一种崭新的效率评估方法。DEA是使用数学规划模型评价具有多个输入和多个输出的“部门”和“单位”(或称决策单元,简记为DMU)间的相对有效性(称为DEA有效)。根据对各DMU观察的数据判断DMU是否为DEA有效,本质上是判断DMU是否位于生产可能集的“前沿面”上。使用DEA对DMU进行效率评价时,可以得到很多在经济学中具有深刻经济含义和背景的管理信息。DEA评价模型特别适用于具有多个输入变量和输出变量的复杂系统,它对决策单元的规模有效性和技术有效性同时进行评价。 当今最具代表性的“经典”DEA模型有:R模型,B模型、FG模型和ST模型。这四个DEA模型之下的(弱)DEA有效性具有各自的经济含义。本文选用C2R模型和G模型,前者可用于评价决策单元的总体有效性,而后者可用于评价决策单元的纯技术有效性。
