云南省图书馆机构用户,欢迎您!
本文描述了连续语音数据库的基本研制过程,提出文本设计等方面使用的语言学、语音学知识,指出在篇章的断句和连续语音的韵律结构方面还存在许多问题有待研究。存在的根本问题在于汉语的句法与韵律的界面方面的研究十分薄弱。
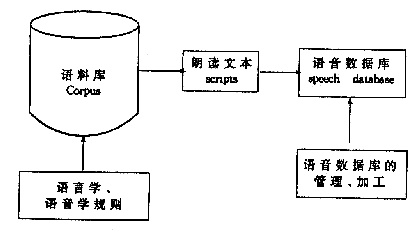 图1 连续语音数据库的建立过程 语音数据库的制作看似简单,但整个建库过程十分繁琐、复杂,其中还涉及到语言的理解和产生两个方面的问题。要真正实现科学性,需要语言学、语音学、心理学、声学及言语技术等综合知识技术。 3.语料库朗读文本的设计 863连续语句文本的设计经历如下步骤。 3.1 断句 文本处理的第一步是断句,目的是为文本处理、朗读以及语音数据的处理等方面带来方便。863 语音识别数据库的连续语句的断句点是在如下标点符号处: “。”,“,”,“;”,“!”,“?”,“:” 为了让发音人不感到困难,原则上把句长限制在20个音节以内。 3.2 拼音转写 为了确定、统计连续语流中的语音现象,必须将文字转写成拼音,要使拼音转换准确,需要有一个很好的词库用于词的切分,并得到准确的拼音文本。 3.3 由拼音生成语音单元 我们将普通话语音的基本成分确定为音子,并设它们是连续语音中的最小音段。普通话的基本音子有37个: a1,a2,a3,b,c,ch,d,e1,e2,e3,er,f,g,h,i1,i2,i3, j,k,l,m,n,ng,o1,o2,p,q,r,s,sh,t,u,x,yv,z,zh,sil 通过基本音子可以方便地描述音节内和音节间的语音现象。有了一个如表1 形式的音节构成表就可以将一个连续话语转写成语音单元串,我们可以任意定义语音单元,如音子、双音子、三音子以及半音节等。 表1 音节构成表 音节由音子生成音节由声母、韵母生成音节 ……………… chu ch—u ch—u chuai ch—u—a2—il ch—uai chuan ch—u—a2—nch—uan chuangch—u—a3—ng ch—uang ……………… 尽管汉语普通话是由一个一个音节连接而成,但在连续语流中,音节的声学表现与孤立音节的情形十分不同,它受到左右音段的影响,偏离了本来位置。在声学层面上描写语流中的音变现象以及音段间的过渡仅用音子是不够的。在863语音连续识别数据库语料设计时, 我们考虑了如表2所示的几种语音单元的覆盖, 其中三音子和韵母—声母结构的数目是根据发音方法和发音部位的变化规律归并而得到的。连续语音中另一个重要的语音现象是韵律结构,一个话语包含着不同的韵律结构,它们与句法、语法结构有着一定的对应关系,但又不是完全一一对应。如表3所示。韵律结构的具体分类有所不同, 它们反应了连续语音的节奏以及更深层次的内涵。〔10〕为了使语料包括不同的韵律结构, 863语音识别和语音合成语料设计中参考清华大学中文系的汉语句型〔11〕考虑了18大类不同句型(由李智强提供)。 表2 863语音数据库的语音单位 语音单位 数目 不含声调区别的音节 401 音节间的双音子 415 音节间的三音子 3035 音节间的韵母—声音 781 表3 韵律结构及句法结构
图1 连续语音数据库的建立过程 语音数据库的制作看似简单,但整个建库过程十分繁琐、复杂,其中还涉及到语言的理解和产生两个方面的问题。要真正实现科学性,需要语言学、语音学、心理学、声学及言语技术等综合知识技术。 3.语料库朗读文本的设计 863连续语句文本的设计经历如下步骤。 3.1 断句 文本处理的第一步是断句,目的是为文本处理、朗读以及语音数据的处理等方面带来方便。863 语音识别数据库的连续语句的断句点是在如下标点符号处: “。”,“,”,“;”,“!”,“?”,“:” 为了让发音人不感到困难,原则上把句长限制在20个音节以内。 3.2 拼音转写 为了确定、统计连续语流中的语音现象,必须将文字转写成拼音,要使拼音转换准确,需要有一个很好的词库用于词的切分,并得到准确的拼音文本。 3.3 由拼音生成语音单元 我们将普通话语音的基本成分确定为音子,并设它们是连续语音中的最小音段。普通话的基本音子有37个: a1,a2,a3,b,c,ch,d,e1,e2,e3,er,f,g,h,i1,i2,i3, j,k,l,m,n,ng,o1,o2,p,q,r,s,sh,t,u,x,yv,z,zh,sil 通过基本音子可以方便地描述音节内和音节间的语音现象。有了一个如表1 形式的音节构成表就可以将一个连续话语转写成语音单元串,我们可以任意定义语音单元,如音子、双音子、三音子以及半音节等。 表1 音节构成表 音节由音子生成音节由声母、韵母生成音节 ……………… chu ch—u ch—u chuai ch—u—a2—il ch—uai chuan ch—u—a2—nch—uan chuangch—u—a3—ng ch—uang ……………… 尽管汉语普通话是由一个一个音节连接而成,但在连续语流中,音节的声学表现与孤立音节的情形十分不同,它受到左右音段的影响,偏离了本来位置。在声学层面上描写语流中的音变现象以及音段间的过渡仅用音子是不够的。在863语音连续识别数据库语料设计时, 我们考虑了如表2所示的几种语音单元的覆盖, 其中三音子和韵母—声母结构的数目是根据发音方法和发音部位的变化规律归并而得到的。连续语音中另一个重要的语音现象是韵律结构,一个话语包含着不同的韵律结构,它们与句法、语法结构有着一定的对应关系,但又不是完全一一对应。如表3所示。韵律结构的具体分类有所不同, 它们反应了连续语音的节奏以及更深层次的内涵。〔10〕为了使语料包括不同的韵律结构, 863语音识别和语音合成语料设计中参考清华大学中文系的汉语句型〔11〕考虑了18大类不同句型(由李智强提供)。 表2 863语音数据库的语音单位 语音单位 数目 不含声调区别的音节 401 音节间的双音子 415 音节间的三音子 3035 音节间的韵母—声音 781 表3 韵律结构及句法结构