云南省图书馆机构用户,欢迎您!
目前影响最为广泛的分级阅读研究是美国分级阅读框架体系,分级种类繁多,分级维度不一。美国英语课程标准将文本复杂性理论写入框架,以定量维度、定性维度以及读者与任务维度作为文本复杂性分析的三大维度,体现了分级阅读研究的最新进展。三个维度的文本复杂性分析框架也为我国分级阅读研究提供了重要启示,我们需要构建定量与定性相统一的文本难度评价标准,确立文本—读者—任务一体化的阅读能力评估模型,打造课内外融通的分级阅读资源开发系统。
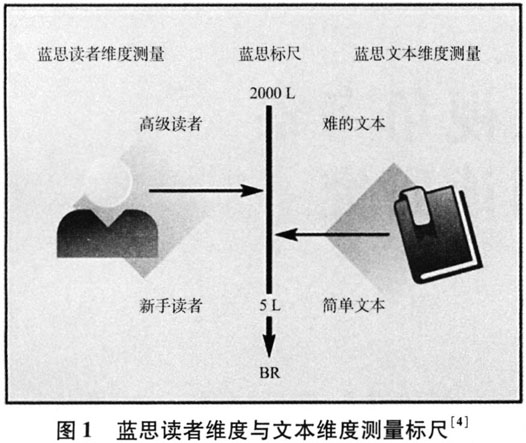 蓝思测评体系的独特之处在于,将读者的阅读能力与文本难度相匹配并进行度量,能够使读者根据其阅读能力进行阅读材料的选择,从而获得个性化阅读体验。同时,蓝思测评体系为教材编写和教师开发阅读资源提供了量化标准。但需要注意的是,蓝思测评体系并不能衡量文本意义和语言结构特点,也无法体现文本对读者的知识需求等指标,这就需要借助定量以外的因素进行文本分析。 (二)文本评价工具 文本评价工具TextEvaluator也是一种定量的分级阅读标准,主要是针对文本难度进行分级,它提供了一种全自动的方法来对选择的阅读文本的复杂性特征进行量化的数据分析。TextEvaluator主要是对经过专业人员编辑的连续性文本进行评分,包括信息文本、文学文本以及信息与文学相结合的文本,它不对非连续性文本和欠规范的连续性文本进行评分,比如表格、列表、诗歌、学生作文等。 TextEvaluator对文本的评分分为四个步骤。第一步是组建两个语料库,一个用于模型开发,一个用于模型验证。在构建语料库时需要考虑两个问题:一是不同的文本长度是否能够对应读者在现实生活中所面临的理解挑战;二是相应因变量是否能够反映人工评判员在评估文本时所考虑的更深层次与结构相关的文本变化因素。TextEvaluator语料库通过训练有素的人工评判员提供材料来解决这些问题,每篇文章类似于学生在学校和家庭阅读中可能得到的材料类型,以证明学生的阅读理解能力。第二步是从每个文本提取基于认知的特征得分向量。Text-Evaluator认为,在对一个文本创建连贯的心理表征过程中,有四种类型的认知过程至关重要:(1)理解构成文本的单个单词,包括从长期记忆中检索词语定义,并根据上下文推断单词含义;(2)利用句法知识定义有意义的论点,并将论点组合成句子,再推断单个句子的含义;(3)使用可观察的文本线索(如重复的实词、明确的连接词)填补空白,并推断跨句子和更大篇幅的文本部分之间的连接;(4)利用先验知识和经验开发更完整、更连贯的关于文本的心理表征,也称为情境模型。在此基础上,TextEvaluator构建了旨在自动检测这些特征的自然语言处理(National Language Processing,简称NLP)工具,并分析了所得特征分数与人工评级之间的关系。第三步是检验文本特征之间的相互关系。由于预计许多保留的特征是中度或高度相关的,因此TextEvaluator主要从多个相关特征中进行实证分析。在每种情况下,TextEvaluator都提出了两步解决方案。首先,利用基于语料库的多维度技术对具有高簇内相关性和低簇间相关性的特征簇进行定位。其次,将根据确定集群定义的线性组合应用于文本表征。这样,将多个相关特征得到的结果进行组合,使复杂性评估模型的度量更加稳定。第四步是建立人工评判文本复杂性的模型。这一步的主要目标是提供一个预测模型,将通过上述特征提取过程获取的结果转化为对真实、不可观察的文本复杂性级别的有效、无偏见的评估。在这个过程中,读者和任务相关因素很关键,因为读者在阅读信息文本和文学文本时需要考虑的文本特征存在显著差异。TextEvaluator提供了针对信息文本、文学文本和混合文本优化的三种不同的复杂性模型。[6]
蓝思测评体系的独特之处在于,将读者的阅读能力与文本难度相匹配并进行度量,能够使读者根据其阅读能力进行阅读材料的选择,从而获得个性化阅读体验。同时,蓝思测评体系为教材编写和教师开发阅读资源提供了量化标准。但需要注意的是,蓝思测评体系并不能衡量文本意义和语言结构特点,也无法体现文本对读者的知识需求等指标,这就需要借助定量以外的因素进行文本分析。 (二)文本评价工具 文本评价工具TextEvaluator也是一种定量的分级阅读标准,主要是针对文本难度进行分级,它提供了一种全自动的方法来对选择的阅读文本的复杂性特征进行量化的数据分析。TextEvaluator主要是对经过专业人员编辑的连续性文本进行评分,包括信息文本、文学文本以及信息与文学相结合的文本,它不对非连续性文本和欠规范的连续性文本进行评分,比如表格、列表、诗歌、学生作文等。 TextEvaluator对文本的评分分为四个步骤。第一步是组建两个语料库,一个用于模型开发,一个用于模型验证。在构建语料库时需要考虑两个问题:一是不同的文本长度是否能够对应读者在现实生活中所面临的理解挑战;二是相应因变量是否能够反映人工评判员在评估文本时所考虑的更深层次与结构相关的文本变化因素。TextEvaluator语料库通过训练有素的人工评判员提供材料来解决这些问题,每篇文章类似于学生在学校和家庭阅读中可能得到的材料类型,以证明学生的阅读理解能力。第二步是从每个文本提取基于认知的特征得分向量。Text-Evaluator认为,在对一个文本创建连贯的心理表征过程中,有四种类型的认知过程至关重要:(1)理解构成文本的单个单词,包括从长期记忆中检索词语定义,并根据上下文推断单词含义;(2)利用句法知识定义有意义的论点,并将论点组合成句子,再推断单个句子的含义;(3)使用可观察的文本线索(如重复的实词、明确的连接词)填补空白,并推断跨句子和更大篇幅的文本部分之间的连接;(4)利用先验知识和经验开发更完整、更连贯的关于文本的心理表征,也称为情境模型。在此基础上,TextEvaluator构建了旨在自动检测这些特征的自然语言处理(National Language Processing,简称NLP)工具,并分析了所得特征分数与人工评级之间的关系。第三步是检验文本特征之间的相互关系。由于预计许多保留的特征是中度或高度相关的,因此TextEvaluator主要从多个相关特征中进行实证分析。在每种情况下,TextEvaluator都提出了两步解决方案。首先,利用基于语料库的多维度技术对具有高簇内相关性和低簇间相关性的特征簇进行定位。其次,将根据确定集群定义的线性组合应用于文本表征。这样,将多个相关特征得到的结果进行组合,使复杂性评估模型的度量更加稳定。第四步是建立人工评判文本复杂性的模型。这一步的主要目标是提供一个预测模型,将通过上述特征提取过程获取的结果转化为对真实、不可观察的文本复杂性级别的有效、无偏见的评估。在这个过程中,读者和任务相关因素很关键,因为读者在阅读信息文本和文学文本时需要考虑的文本特征存在显著差异。TextEvaluator提供了针对信息文本、文学文本和混合文本优化的三种不同的复杂性模型。[6]