云南省图书馆机构用户,欢迎您!
人工智能与古文字学交叉研究十分重要,开展这项研究既需要人工收集和标注大量数据,同时也需结合恰当的技术。在数据处理方面,数据集建设过程中尽量丰富了单字数量以及字图总量。数据中的字图包括拓本和摹本,其中拓本多带有斑点噪声,降低噪声有助于提高文字识别的准确率。数据中古文字隶定体的显示也是要重点解决的问题。在文字自动识别方面,利用了深度学习算法开展智能识别,从实验结果看,准确率达到八成以上,这是在大规模识别任务下达到的效果,证明了利用人工智能技术识别古文字形体是可行的。分析错误数据可以发现,数据量与形近字是影响识别准确率的关键因素。除了识别以外,知识图谱技术也很重要,建设古文字知识图谱一方面可以实现对古文字知识体系的多角度展示;另一方面也可计算字形中偏旁及构形的相似度,智能寻找出字形之间的联系。
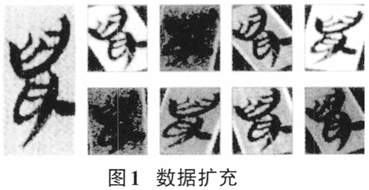 (二)字体的生成与显示
(二)字体的生成与显示  (三)拓本的降噪与处理 甲骨文与金文的主要呈现方式是拓本,而由于文字载体本身的残损、锈蚀等原因,拓本往往会出现一些斑点、泐痕等非文字笔画痕迹,图像中这些非必要的或多余的干扰信息在计算机领域被称作噪声。带有噪声的拓本如
(三)拓本的降噪与处理 甲骨文与金文的主要呈现方式是拓本,而由于文字载体本身的残损、锈蚀等原因,拓本往往会出现一些斑点、泐痕等非文字笔画痕迹,图像中这些非必要的或多余的干扰信息在计算机领域被称作噪声。带有噪声的拓本如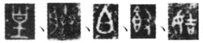 ,类似情况一般不会给古文字研究者造成影响,因为专家凭借知识积累以及研究经验,很容易排除这些噪声,但是对于人工智能模型而言,噪声会形成较大的障碍,所以在人工智能与古文字的交叉研究中,降低噪声是很重要的步骤。以往一些研究文字识别的学者,较多利用的是摹本而非拓本,最主要的原因就是拓本存在噪声。对拓本图像进行降噪处理是十分必要的工作。 我们先后采用腐蚀化、骨架化、膨胀化、二值化的方法,最终实现了图像降噪的目标。例如伯椃虘簋铭文中的“皇”字作
,类似情况一般不会给古文字研究者造成影响,因为专家凭借知识积累以及研究经验,很容易排除这些噪声,但是对于人工智能模型而言,噪声会形成较大的障碍,所以在人工智能与古文字的交叉研究中,降低噪声是很重要的步骤。以往一些研究文字识别的学者,较多利用的是摹本而非拓本,最主要的原因就是拓本存在噪声。对拓本图像进行降噪处理是十分必要的工作。 我们先后采用腐蚀化、骨架化、膨胀化、二值化的方法,最终实现了图像降噪的目标。例如伯椃虘簋铭文中的“皇”字作 《铭图》5085),该形左侧和右上部都有噪声。在降噪过程中(参图2),首先对其进行“腐蚀化”操作⑥,尽量减少拓本中的小面积独立噪声,当然这一操作会使文字笔画受到部分影响;接着采取“骨架化”操作,提取拓本中文字的形体骨干,噪声多数会在前两个步骤中被排除;然后进行“膨胀化”操作,将形体骨干加粗,重新变成丰满的笔画;最后是“二值化”操作,将拓本处理成白色文字和黑色背景的形式。在实际研发过程中,数据集中每一个文字拓本都会经过这一降噪过程,从而弱化图像中的噪声干扰,提高模型对笔画特征的提取能力,增强模型分类的准确性。
《铭图》5085),该形左侧和右上部都有噪声。在降噪过程中(参图2),首先对其进行“腐蚀化”操作⑥,尽量减少拓本中的小面积独立噪声,当然这一操作会使文字笔画受到部分影响;接着采取“骨架化”操作,提取拓本中文字的形体骨干,噪声多数会在前两个步骤中被排除;然后进行“膨胀化”操作,将形体骨干加粗,重新变成丰满的笔画;最后是“二值化”操作,将拓本处理成白色文字和黑色背景的形式。在实际研发过程中,数据集中每一个文字拓本都会经过这一降噪过程,从而弱化图像中的噪声干扰,提高模型对笔画特征的提取能力,增强模型分类的准确性。