云南省图书馆机构用户,欢迎您!
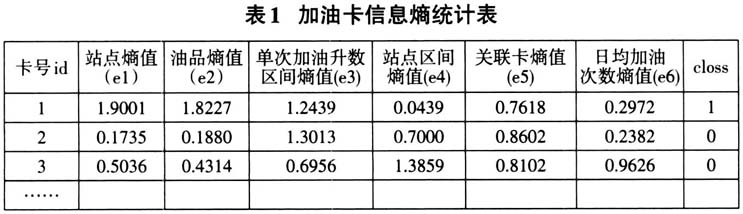
 在审计实践中,套现行为还存在“升级”现象。套现人相互勾结,快递交换加油卡套现,以规避数据特征,但往往最多规避一到两项。因此,套现综合特征与正常加油一定存在差异。这种差异可用信息熵来量化,而套现行为与信息熵的逻辑关系可用机器学习计算。基于此,本文尝试开发了防范加油卡套现审计模型,具体实施步骤如下。 (一)加油卡特征数据提取 加油卡记录主要包括加油卡号、时间、油品、交易发生的加油站、交易升数等字段。本案例中,根据加油卡记录整理出某石油公司半年内的28万张加油卡数据。随后,统计新建套现特征字段二维表。字段包括加油卡号、平均加油升数、最高加油升数、最低加油升数、去过的加油站数量、日均加油次升数、日均加油次数。 (二)特征数据熵值计算生成二维表 根据特征字段二维表计算每张加油卡特征字段值与平均值偏离的混乱程度(信息熵),得到站点熵值(e1)、油品熵值(e2)、单次加油升数区间熵值(e3)、站点区间熵值(e4)、关联卡熵值(e5)、日均加油次数熵值(e6),生成熵值表。 以单次加油升数区间熵值、油品熵值为例: 单次加油升数区间熵值。取加油卡近半年内的全部加油升数记录[10升,15升,30升,40升,50升]作为不同的区间段,分别统计每张加油卡单次加油记录落在各个区间内的次数,得到以“加油卡号”和“单次加油升数区间”为关键值,该区间消费次数占该卡全部消费次数的比例“区间消费次数占比”为计算值的统计数据。 油品熵值。统计加油卡近半年内对于不同油品的消费次数,得到以“加油卡号”和“油品”为关键值,不同油品消费次数占该卡全部消费次数的比例——“油品消费次数占比”为计算值的统计数据。 根据信息熵公式计算各字段熵值。计算结果输出为加油卡信息熵统计表,简化后表格如表1所示。每张加油卡为一条记录,每条记录6列熵值字段。增加一个字段class作为分类标签,正常加油卡class值为0,套现加油卡class值为1。 (三)机器学习确定熵值影响加油卡套现的权重 获得每张加油卡6个特征字段的熵值后,需要用机器学习的方法训练一个分类器,根据每个字段的熵值将加油卡分为套现卡和正常卡两类。
在审计实践中,套现行为还存在“升级”现象。套现人相互勾结,快递交换加油卡套现,以规避数据特征,但往往最多规避一到两项。因此,套现综合特征与正常加油一定存在差异。这种差异可用信息熵来量化,而套现行为与信息熵的逻辑关系可用机器学习计算。基于此,本文尝试开发了防范加油卡套现审计模型,具体实施步骤如下。 (一)加油卡特征数据提取 加油卡记录主要包括加油卡号、时间、油品、交易发生的加油站、交易升数等字段。本案例中,根据加油卡记录整理出某石油公司半年内的28万张加油卡数据。随后,统计新建套现特征字段二维表。字段包括加油卡号、平均加油升数、最高加油升数、最低加油升数、去过的加油站数量、日均加油次升数、日均加油次数。 (二)特征数据熵值计算生成二维表 根据特征字段二维表计算每张加油卡特征字段值与平均值偏离的混乱程度(信息熵),得到站点熵值(e1)、油品熵值(e2)、单次加油升数区间熵值(e3)、站点区间熵值(e4)、关联卡熵值(e5)、日均加油次数熵值(e6),生成熵值表。 以单次加油升数区间熵值、油品熵值为例: 单次加油升数区间熵值。取加油卡近半年内的全部加油升数记录[10升,15升,30升,40升,50升]作为不同的区间段,分别统计每张加油卡单次加油记录落在各个区间内的次数,得到以“加油卡号”和“单次加油升数区间”为关键值,该区间消费次数占该卡全部消费次数的比例“区间消费次数占比”为计算值的统计数据。 油品熵值。统计加油卡近半年内对于不同油品的消费次数,得到以“加油卡号”和“油品”为关键值,不同油品消费次数占该卡全部消费次数的比例——“油品消费次数占比”为计算值的统计数据。 根据信息熵公式计算各字段熵值。计算结果输出为加油卡信息熵统计表,简化后表格如表1所示。每张加油卡为一条记录,每条记录6列熵值字段。增加一个字段class作为分类标签,正常加油卡class值为0,套现加油卡class值为1。 (三)机器学习确定熵值影响加油卡套现的权重 获得每张加油卡6个特征字段的熵值后,需要用机器学习的方法训练一个分类器,根据每个字段的熵值将加油卡分为套现卡和正常卡两类。