云南省图书馆机构用户,欢迎您!
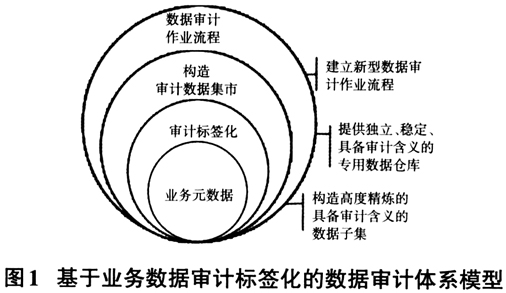 (一)审计标签化 1.标签的定义 审计数据标签化是对某数据集合的一种或多种稳定的审计特征进行分析和描述,由多个可定性的属性条件或特征标识组合而成,从而使该数据集合脱离元数据属性,形成高度精炼的、具备审计含义的数据子集。 2.标签的建立 笔者采用类自然语言构造基础审计标签库,通过多种方式建模,对目标审计数据输出标签,实现对各系统业务数据的标签化,将元数据中具备审计价值的信息剥离出来。 (1)逻辑层次 审计数据标签化构成逻辑模型如图2所示。
(一)审计标签化 1.标签的定义 审计数据标签化是对某数据集合的一种或多种稳定的审计特征进行分析和描述,由多个可定性的属性条件或特征标识组合而成,从而使该数据集合脱离元数据属性,形成高度精炼的、具备审计含义的数据子集。 2.标签的建立 笔者采用类自然语言构造基础审计标签库,通过多种方式建模,对目标审计数据输出标签,实现对各系统业务数据的标签化,将元数据中具备审计价值的信息剥离出来。 (1)逻辑层次 审计数据标签化构成逻辑模型如图2所示。 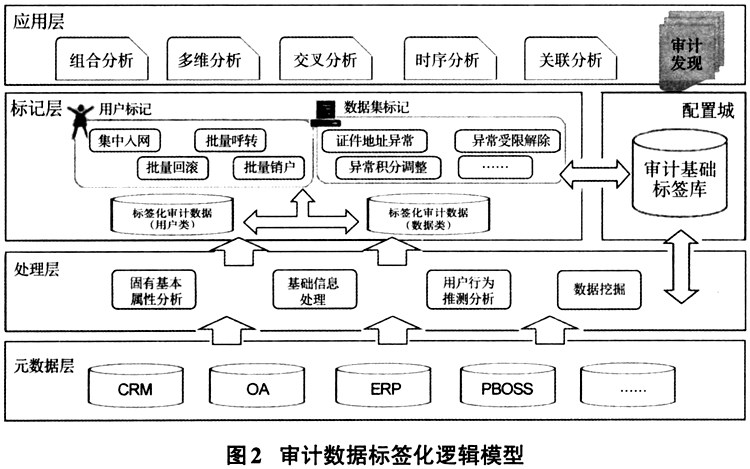 该模型由元数据层、处理层、标记层及应用层组成,在标记层与配置域进行参数交互。 元数据层向所有标记过程提供元数据,这里主要是CRM、OA、ERP等结构化业务运营数据。 处理层从元数据层获取数据后,按照预先定义的类自然语言审计标签,通过固有基本属性分析、基础信息处理、用户行为推测分析、数据挖掘4个方法建模,对目标审计数据进行分析处理,向标记层输出已标签化的审计数据。 标记层负责对标记后的审计数据进行分类汇总,形成可被审计使用的标签化数据。 应用层主要是提供给审计人员使用,让审计人员结合审计项目需要,对标签化数据进行抽取,采用交叉、组合、时序、关联等分析,结合访谈、审阅等,最终形成审计发现。 (2)举例 ①固有基本属性分析 通过对业务数据中已定义的结构化数据信息对其进行建模,得出符合审计逻辑的标签。以主标签“异常证件地址”为例,对用户的基本属性信息“证件地址”进行分析建模: 子标签为“同址不同号”,口径为:用户证件地址完全相同,但证件号不同。 子标签为“证址不符”,口径为:用户证件地址省份与证号前2位归属省编号不一致。如:XX省份证件号前2位为34,但证件地址省份为其他省(其中也存在正常的转户籍情况)。 ②基础信息处理 通过对基础信息进行分析处理,构造模型,得出符合审计逻辑的标签。以主标签“集中呼转”为例,对用户呼叫转移业务操作记录、通话记录进行关联分析建模。 口径为:首先分析通过后台工号(如:10086,网厅等)受理呼叫转移操作,超过N个用户呼转至同一号码;然后分析该批用户连续M个月的通话记录,对其中周期内仅通话A次或通话时长低于B分钟的定义为“集中呼转”。
该模型由元数据层、处理层、标记层及应用层组成,在标记层与配置域进行参数交互。 元数据层向所有标记过程提供元数据,这里主要是CRM、OA、ERP等结构化业务运营数据。 处理层从元数据层获取数据后,按照预先定义的类自然语言审计标签,通过固有基本属性分析、基础信息处理、用户行为推测分析、数据挖掘4个方法建模,对目标审计数据进行分析处理,向标记层输出已标签化的审计数据。 标记层负责对标记后的审计数据进行分类汇总,形成可被审计使用的标签化数据。 应用层主要是提供给审计人员使用,让审计人员结合审计项目需要,对标签化数据进行抽取,采用交叉、组合、时序、关联等分析,结合访谈、审阅等,最终形成审计发现。 (2)举例 ①固有基本属性分析 通过对业务数据中已定义的结构化数据信息对其进行建模,得出符合审计逻辑的标签。以主标签“异常证件地址”为例,对用户的基本属性信息“证件地址”进行分析建模: 子标签为“同址不同号”,口径为:用户证件地址完全相同,但证件号不同。 子标签为“证址不符”,口径为:用户证件地址省份与证号前2位归属省编号不一致。如:XX省份证件号前2位为34,但证件地址省份为其他省(其中也存在正常的转户籍情况)。 ②基础信息处理 通过对基础信息进行分析处理,构造模型,得出符合审计逻辑的标签。以主标签“集中呼转”为例,对用户呼叫转移业务操作记录、通话记录进行关联分析建模。 口径为:首先分析通过后台工号(如:10086,网厅等)受理呼叫转移操作,超过N个用户呼转至同一号码;然后分析该批用户连续M个月的通话记录,对其中周期内仅通话A次或通话时长低于B分钟的定义为“集中呼转”。