云南省图书馆机构用户,欢迎您!
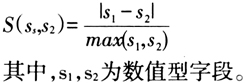 (3)字符型字段相似度计算方法:对于字符型字段,一个字段可以看成是一个字符串,字符串的相似检测最主要的方法是基于编辑距离算法。通过采用编辑距离算法,可以计算出两个字段间的编辑距离,进而计算出字符型字段的相似度(图1)。 综上可知,目前常用的审计数据分析方法多是针对结构化数据。大数据环境下,需要审计的不仅仅是数据库中的结构化数据,还包括一些政策文件、项目信息等非结构化数据。因此,常用的审计方法不能满足大数据环境下审计工作的需要,其中,研究如何对文本数据进行审计非常重要。 三、基于文本数据分析的大数据审计方法 (一)基于文本数据分析的大数据审计方法原理
(3)字符型字段相似度计算方法:对于字符型字段,一个字段可以看成是一个字符串,字符串的相似检测最主要的方法是基于编辑距离算法。通过采用编辑距离算法,可以计算出两个字段间的编辑距离,进而计算出字符型字段的相似度(图1)。 综上可知,目前常用的审计数据分析方法多是针对结构化数据。大数据环境下,需要审计的不仅仅是数据库中的结构化数据,还包括一些政策文件、项目信息等非结构化数据。因此,常用的审计方法不能满足大数据环境下审计工作的需要,其中,研究如何对文本数据进行审计非常重要。 三、基于文本数据分析的大数据审计方法 (一)基于文本数据分析的大数据审计方法原理  大数据环境下大量的文本数据使审计人员分析的难度越来越大,传统的浏览和筛选等方法无法满足大数据环境下文本数据等非结构化数据审计的需要,对非结构化数据进行可视化分析,是大数据审计研究与应用的重要内容。将文本数据中的内容或规律以视觉符号的形式展示给审计人员,有助于审计人员利用视觉感知的优势来快速获取大数据中蕴涵的重要信息,从而发现审计线索。对大数据审计来说,文本内容可视化主要是为了快速获取文本数据内容的重点,快速理解文本的主要内容,可以采用基于词频的可视化技术,如采用TF-IDF技术、标签云的可视化形式进行展示。 基于文本数据分析的大数据审计方法原理可概述为:根据对被审计单位的调查,在访谈和现场观察等基础上,采集被审计单位的内外部相关信息如政策文件、项目信息、董事会会议记录、董事会会议决议、总经理办公会记录、会议决议单、办公会通知、办公文件、项目安排、相关年度资金计划安排、项目工作总结、相关项目绩效评价报告等非结构化数据,以及从外部网上公开数据源采集来的相关文本数据;然后,在审计大数据预处理的基础上,基于“总体分析、发现疑点、分散核查、系统研究”的审计思路,采用大数据工具对相关文本数据进行分析,审计人员通过对可视化的分析结果进行观察,快速从被审计大数据信息中发现异常数据,获得审计线索;在此基础上,通过对这些结果数据做进一步的延伸审计和审计事实确认,最终获得审计证据。综上分析,基于文本数据分析的大数据审计方法原理如图2所示。 (二)相似度分析 1.相似度分析方法的原理 大数据环境下,相似度分析是目前有效的一种文本数据审计方法。大数据审计环境下,有时需要分析文本数据之间是否相似,成熟可行的方法可以采用?TF-IDF(Term Frequency-Inverse Document? Frequency,词频-逆文档频率)技术,它是一种常用的自然语言处理(NIP,Natural Language Processing)方法,TF-IDF的主要思想是:根据字词的在文本中出现的频率和在整个文本库中出现的频率来计算一个字词在整个文本库中的重要程度。如果某个词或短语在一篇文章中出现的频率TF高,并且在其他文本中出现的很少,则认为该词或者短语具有很好的代表性,适合用来分类。TF-IDF可用于比较两个文本文件相似程度、文本聚类、文本分类等方面。TF-IDF的计算步骤如下:
大数据环境下大量的文本数据使审计人员分析的难度越来越大,传统的浏览和筛选等方法无法满足大数据环境下文本数据等非结构化数据审计的需要,对非结构化数据进行可视化分析,是大数据审计研究与应用的重要内容。将文本数据中的内容或规律以视觉符号的形式展示给审计人员,有助于审计人员利用视觉感知的优势来快速获取大数据中蕴涵的重要信息,从而发现审计线索。对大数据审计来说,文本内容可视化主要是为了快速获取文本数据内容的重点,快速理解文本的主要内容,可以采用基于词频的可视化技术,如采用TF-IDF技术、标签云的可视化形式进行展示。 基于文本数据分析的大数据审计方法原理可概述为:根据对被审计单位的调查,在访谈和现场观察等基础上,采集被审计单位的内外部相关信息如政策文件、项目信息、董事会会议记录、董事会会议决议、总经理办公会记录、会议决议单、办公会通知、办公文件、项目安排、相关年度资金计划安排、项目工作总结、相关项目绩效评价报告等非结构化数据,以及从外部网上公开数据源采集来的相关文本数据;然后,在审计大数据预处理的基础上,基于“总体分析、发现疑点、分散核查、系统研究”的审计思路,采用大数据工具对相关文本数据进行分析,审计人员通过对可视化的分析结果进行观察,快速从被审计大数据信息中发现异常数据,获得审计线索;在此基础上,通过对这些结果数据做进一步的延伸审计和审计事实确认,最终获得审计证据。综上分析,基于文本数据分析的大数据审计方法原理如图2所示。 (二)相似度分析 1.相似度分析方法的原理 大数据环境下,相似度分析是目前有效的一种文本数据审计方法。大数据审计环境下,有时需要分析文本数据之间是否相似,成熟可行的方法可以采用?TF-IDF(Term Frequency-Inverse Document? Frequency,词频-逆文档频率)技术,它是一种常用的自然语言处理(NIP,Natural Language Processing)方法,TF-IDF的主要思想是:根据字词的在文本中出现的频率和在整个文本库中出现的频率来计算一个字词在整个文本库中的重要程度。如果某个词或短语在一篇文章中出现的频率TF高,并且在其他文本中出现的很少,则认为该词或者短语具有很好的代表性,适合用来分类。TF-IDF可用于比较两个文本文件相似程度、文本聚类、文本分类等方面。TF-IDF的计算步骤如下: