云南省图书馆机构用户,欢迎您!
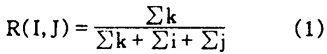 也就是相关度等于双方共有要素的和与双方所有共有要素及所有各具要素的和的比值。 这里我们看看郑锦全关于汉语方言相关程度的计量研究。郑锦全提出根据方言中某些词汇形式和音韵形式的有无,运用统计学里的皮尔逊相关系数公式,来计算方言间的相关系数值,并把它作为衡量方言亲疏程度的指标(郑锦全,1988)。这里且不说他的研究中没有将相似度和相关度两个概念进行必要界划,以致统计研究中常常相混,特别是抛开相似度而以相关度为衡量方言亲疏程度的唯一指标,可能会导致统计分析结论上的误差;单从统计指标的设置上看,把皮尔逊相关系数式套用到方言关系上是否合适就值得考虑。就语言系统关系来说,相关程度的高低,应取决于相互间构成要素中相同项总量的多少。没有相同项,我们就说它们没有关系;相同项多些,我们就说它们相关程度高些,反之就低些。因此语言系统之间应该只有完全不相关和正相关两种关系,不应存在负相关关系,其相关系数值都应在0—1之间,不允许出现负值。而皮尔逊相关系数式是用以计算两变量的线性关系的密切程度的,其计算结果可在-1到+1之间,允许出现负值。如果用皮尔逊相关为语言相关程度的测量指标,就意味着语言之间可能会出现负相关的情况,这不合于语言实际。再者,皮尔逊相关系数的正负值反映的是相关的不同方向或性质,其绝对值的大小才显示相关程度的高低。这样的话,如果同为负值,绝对值大我们就要说它相关程度高,绝对值小我们就要说它相关程度低,而事实上是负值的绝对值越大,语言间的差异量就越多而共有量就越少。如果把差异量大共有量小的情况看为相关程度高,反之看为相关程度低,这在观念上也是不好接受的。所以,把皮尔逊相关系数当作测量语言系统相关程度的指标,未必是一个最好的选择。我们认为,如用方言间相同因子的和与相同因子及不同因子之和的比值,来作为衡量相关程度的指标,可能才会更简捷而客观。王士元、沈钟伟曾提出,采用分类学中普遍使用的Jaccard的相关系数计算法才更为合理(王士元、沈钟伟,1992)。Jaccard计算法实际就是计算双方共有量与共有量及差别量之和的比值,其计算结果数值范围也都在0—1之间。他们的意见应该是对的。 确定方言相关度统计指标有两点要注意。第一点,相关度指标应包含两总体所有构成要素,而不应只局限于对应要素上。不同方言中可能都存在一些独特的构成要素,这些要素无法与别的方言形成对应。仅以对应要素进行测量,就会因缺漏这方面的数据而使相关统计出现误差。这也是我们强调相似度与相关度指标需要区分的原因之一:相似度只能在对应要素之间进行测量,而相关度则可以而且应该顾及所有构成要素。第二点,统计指标所用的单位要放到能反映相关程度差别的层面上去。比如进行词汇相关度统计时若只以词汇形式为单位,并依其有无进行计算,会忽视语素、构词方式等在相关程度上所起的作用,使相关度本当大小有别的变得没有差别了,因而导致统计误差。这一点王士元、沈钟伟已给予指出(王士元、沈钟伟,1992)。另一方面,也可能会把本当没有差别误作差别看待,这同样会导致统计上的误差。例如“蝉”这样的词,如果不考虑词尾的差别,在《汉语方言词汇》中就有“截溜”(济南)、“蝉溜”(合肥)、“虮溜子”(扬州)、“知了”(苏州)、“知龙”(温州)、“蝉了子”(长沙)、[tζia[55]·lu·子](南昌)等词形,古语词中还有“蜩”、“是劳”、“帝劳”、“是乐”、“刀劳”、“召僚”、“蜘僚”(上诸字本都从虫)等词形,若以词汇形式为单位进行统计,它们都将互不相关。实际上这些方言词形都不过是“知了”一词的方言音转,古语词除“蜩”当即“是劳”等的合音外,余也当为“知了”的古今音转。这些词形虽个个不同,但应仍然是同一个词(是只有同一个词素的单纯词),差别只在古今方音音转,但那是音韵的问题,不是词汇的问题。比如“猫”,此地念miao[55],彼地念mao[55],你能说它们是毫不相关的两个词么?语音相关度统计也是如此,若以语音形式为单位就会忽视音素特征在语音相关度上所起的作用,导致统计误差。比如中古匣母字在现代17个主要方言中有[x]、[u]、[k]、[i]、[v]、[k]、[s]、[y]、[f]、[h]、[g]、[ng]、[j]、[t]、[w]、[l]等等共31种不同形式,如果以语音形式为统计单位,那么它们都将互不相关。但我们凭语言直觉和语言知识就能判断它们之间在相关程度上应有大小之差。所以要精确测定语音系统相关程度的话,不能不考虑把统计单位“下放”到语音构成的更小的因子上去。
也就是相关度等于双方共有要素的和与双方所有共有要素及所有各具要素的和的比值。 这里我们看看郑锦全关于汉语方言相关程度的计量研究。郑锦全提出根据方言中某些词汇形式和音韵形式的有无,运用统计学里的皮尔逊相关系数公式,来计算方言间的相关系数值,并把它作为衡量方言亲疏程度的指标(郑锦全,1988)。这里且不说他的研究中没有将相似度和相关度两个概念进行必要界划,以致统计研究中常常相混,特别是抛开相似度而以相关度为衡量方言亲疏程度的唯一指标,可能会导致统计分析结论上的误差;单从统计指标的设置上看,把皮尔逊相关系数式套用到方言关系上是否合适就值得考虑。就语言系统关系来说,相关程度的高低,应取决于相互间构成要素中相同项总量的多少。没有相同项,我们就说它们没有关系;相同项多些,我们就说它们相关程度高些,反之就低些。因此语言系统之间应该只有完全不相关和正相关两种关系,不应存在负相关关系,其相关系数值都应在0—1之间,不允许出现负值。而皮尔逊相关系数式是用以计算两变量的线性关系的密切程度的,其计算结果可在-1到+1之间,允许出现负值。如果用皮尔逊相关为语言相关程度的测量指标,就意味着语言之间可能会出现负相关的情况,这不合于语言实际。再者,皮尔逊相关系数的正负值反映的是相关的不同方向或性质,其绝对值的大小才显示相关程度的高低。这样的话,如果同为负值,绝对值大我们就要说它相关程度高,绝对值小我们就要说它相关程度低,而事实上是负值的绝对值越大,语言间的差异量就越多而共有量就越少。如果把差异量大共有量小的情况看为相关程度高,反之看为相关程度低,这在观念上也是不好接受的。所以,把皮尔逊相关系数当作测量语言系统相关程度的指标,未必是一个最好的选择。我们认为,如用方言间相同因子的和与相同因子及不同因子之和的比值,来作为衡量相关程度的指标,可能才会更简捷而客观。王士元、沈钟伟曾提出,采用分类学中普遍使用的Jaccard的相关系数计算法才更为合理(王士元、沈钟伟,1992)。Jaccard计算法实际就是计算双方共有量与共有量及差别量之和的比值,其计算结果数值范围也都在0—1之间。他们的意见应该是对的。 确定方言相关度统计指标有两点要注意。第一点,相关度指标应包含两总体所有构成要素,而不应只局限于对应要素上。不同方言中可能都存在一些独特的构成要素,这些要素无法与别的方言形成对应。仅以对应要素进行测量,就会因缺漏这方面的数据而使相关统计出现误差。这也是我们强调相似度与相关度指标需要区分的原因之一:相似度只能在对应要素之间进行测量,而相关度则可以而且应该顾及所有构成要素。第二点,统计指标所用的单位要放到能反映相关程度差别的层面上去。比如进行词汇相关度统计时若只以词汇形式为单位,并依其有无进行计算,会忽视语素、构词方式等在相关程度上所起的作用,使相关度本当大小有别的变得没有差别了,因而导致统计误差。这一点王士元、沈钟伟已给予指出(王士元、沈钟伟,1992)。另一方面,也可能会把本当没有差别误作差别看待,这同样会导致统计上的误差。例如“蝉”这样的词,如果不考虑词尾的差别,在《汉语方言词汇》中就有“截溜”(济南)、“蝉溜”(合肥)、“虮溜子”(扬州)、“知了”(苏州)、“知龙”(温州)、“蝉了子”(长沙)、[tζia[55]·lu·子](南昌)等词形,古语词中还有“蜩”、“是劳”、“帝劳”、“是乐”、“刀劳”、“召僚”、“蜘僚”(上诸字本都从虫)等词形,若以词汇形式为单位进行统计,它们都将互不相关。实际上这些方言词形都不过是“知了”一词的方言音转,古语词除“蜩”当即“是劳”等的合音外,余也当为“知了”的古今音转。这些词形虽个个不同,但应仍然是同一个词(是只有同一个词素的单纯词),差别只在古今方音音转,但那是音韵的问题,不是词汇的问题。比如“猫”,此地念miao[55],彼地念mao[55],你能说它们是毫不相关的两个词么?语音相关度统计也是如此,若以语音形式为单位就会忽视音素特征在语音相关度上所起的作用,导致统计误差。比如中古匣母字在现代17个主要方言中有[x]、[u]、[k]、[i]、[v]、[k]、[s]、[y]、[f]、[h]、[g]、[ng]、[j]、[t]、[w]、[l]等等共31种不同形式,如果以语音形式为统计单位,那么它们都将互不相关。但我们凭语言直觉和语言知识就能判断它们之间在相关程度上应有大小之差。所以要精确测定语音系统相关程度的话,不能不考虑把统计单位“下放”到语音构成的更小的因子上去。