云南省图书馆机构用户,欢迎您!
类型学中常用语义地图来分析和展示跨语言的差异,但是如何在已知数据的基础上构建语义地图?传统的方法未考虑到出现频率,而且往往有多个地图的可能,给我们的地图仅仅是跨语言变项演示中的某一可能的地图,所以传统方法需要批判。本文将展示一种新的方法论意义上的操作,通过一步步地吸收出现频率的数据,在优先选择和优先赋值的原则上,建立“加权最少边地图”。我们也将它运用到更广泛的语法研究领域,并给出一些有关人类社会的普遍性结论。我们还设立了一个指数,以评估给定数据中的隐性控制程度。
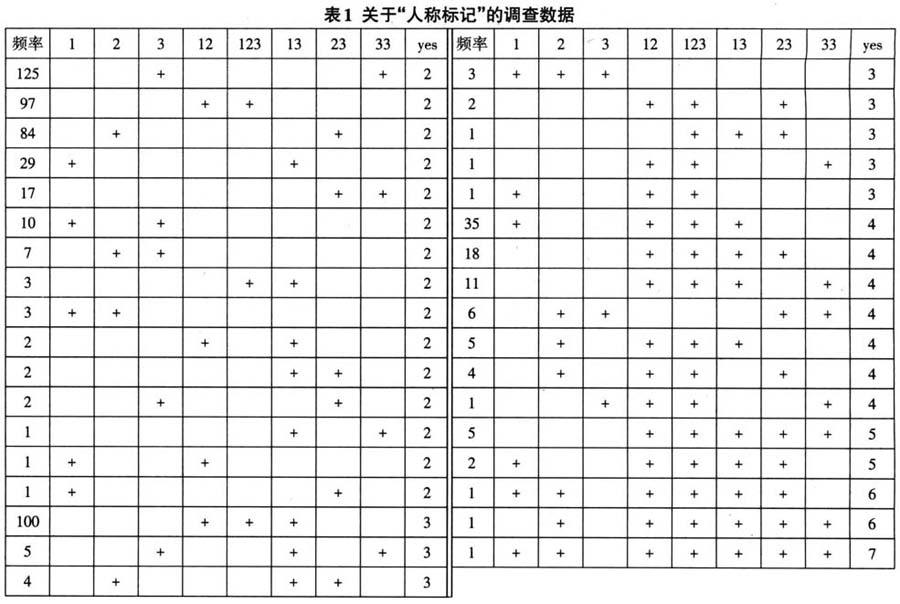 说明:其中第一行表示共有八个项目,其意义为:1言者,如I;2听者,如you;3言者与听者之外的第三者,如he/she/it;12包括言者与听者,如we(复数包括式);123所有各方,有多个听者,如we(复数包括式);13不包括听者,只包括言者和第三者,如we(排除式);23不包括言者,只包括听者和第三者,如you;33不包括言者和听者,只是多个第三者,如they。 表中每一行都代表语言中存在的一个组合,它在八个调查项目中有不同的yes(用“+”表示)和no(用空白格表示)分布情况,一共有35种不同的组合。每一种组合第一列的频率数字代表拥有这一意义组合的语言形式的数字。右边的最后一列“yes”反映每行中所共现的“+”号的数量。 将表中数据全部反映出来,就得到图1这样一张完整加权的语义地图。这图非常复杂。但是地图越复杂,语义关系反而越不清晰,可以从图中找到的隐性规律越少。这是因为图中有不少“回路”(loop),每一条回路都会破坏规律性。
说明:其中第一行表示共有八个项目,其意义为:1言者,如I;2听者,如you;3言者与听者之外的第三者,如he/she/it;12包括言者与听者,如we(复数包括式);123所有各方,有多个听者,如we(复数包括式);13不包括听者,只包括言者和第三者,如we(排除式);23不包括言者,只包括听者和第三者,如you;33不包括言者和听者,只是多个第三者,如they。 表中每一行都代表语言中存在的一个组合,它在八个调查项目中有不同的yes(用“+”表示)和no(用空白格表示)分布情况,一共有35种不同的组合。每一种组合第一列的频率数字代表拥有这一意义组合的语言形式的数字。右边的最后一列“yes”反映每行中所共现的“+”号的数量。 将表中数据全部反映出来,就得到图1这样一张完整加权的语义地图。这图非常复杂。但是地图越复杂,语义关系反而越不清晰,可以从图中找到的隐性规律越少。这是因为图中有不少“回路”(loop),每一条回路都会破坏规律性。 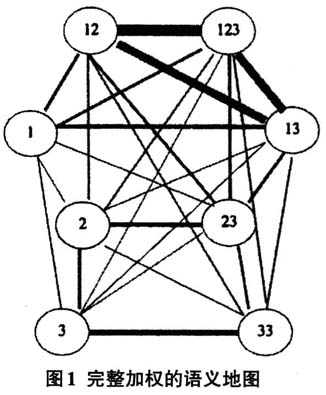 之所以会形成图1这样的局面,是因为在调查的数据中,混入了一些“噪声”,即有的联系在调查中很少出现,它们不反映必然性规律,而仅仅是反映一些偶然现象,即在历史演变中因为某个特殊的原因造成的特殊的现象,但它们对“规律性”的数据会产生干扰。我们需要对这些噪声进行过滤。 Cysouw(2007)的办法,是将上述语义地图中的某些连线删除,从而构成更为简约的地图。我们称之为“降噪”的过程,如图2:
之所以会形成图1这样的局面,是因为在调查的数据中,混入了一些“噪声”,即有的联系在调查中很少出现,它们不反映必然性规律,而仅仅是反映一些偶然现象,即在历史演变中因为某个特殊的原因造成的特殊的现象,但它们对“规律性”的数据会产生干扰。我们需要对这些噪声进行过滤。 Cysouw(2007)的办法,是将上述语义地图中的某些连线删除,从而构成更为简约的地图。我们称之为“降噪”的过程,如图2: 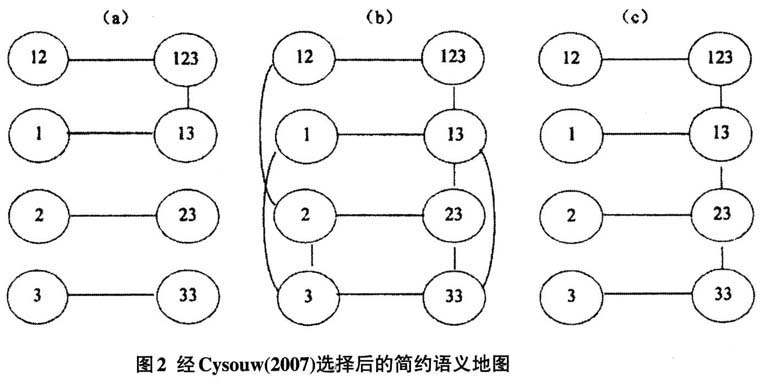 这些地图的简约程度各不相同,究竟哪张图更反映语言事实?更为重要的问题是,为什么是保留这些连线,而不是其他的连线?“降噪”的依据是什么?这是一个大问题。 Cysouw(2007:19)的操作方法中有一个漏洞。如在图1中,“12-13”这条连线的出现次数为“181”,意味着有181个形式中,同时出现12和13的语义内容。共现次数越高,则两个项目之间的连线越粗;反之,连线越细。这一次数本应作为删或留的标准,但虽然“12-13”之间的连线相当粗(是图中第三粗的线),Cysouw却将它删除了,不再出现在图2中,为什么? 郭锐(2012b:115-116)对计算方法做了改进,引入了“关联度”的概念;马腾(2015:201)详细解说:两个点(基元)之间关联度的计算公式为“兼有数/总数”,其中,点A、B的兼有数指A、B的共现次数;而点A、B的总数指A、B各自出现次数之和,再减去它们的共现次数。 不过,这一计算仍然存在很大的问题,在郭锐(2012b)的计算中,“12-13”之间的关联度仍高到59.54%,排名第五,比排名第六的“1-13”的31.48%高出不少;而在马腾(2015:202)中,“12-13”的兼有数被从郭锐(2015:169)中的“181次”一下下降到了“2次”,但却未说明原因。
这些地图的简约程度各不相同,究竟哪张图更反映语言事实?更为重要的问题是,为什么是保留这些连线,而不是其他的连线?“降噪”的依据是什么?这是一个大问题。 Cysouw(2007:19)的操作方法中有一个漏洞。如在图1中,“12-13”这条连线的出现次数为“181”,意味着有181个形式中,同时出现12和13的语义内容。共现次数越高,则两个项目之间的连线越粗;反之,连线越细。这一次数本应作为删或留的标准,但虽然“12-13”之间的连线相当粗(是图中第三粗的线),Cysouw却将它删除了,不再出现在图2中,为什么? 郭锐(2012b:115-116)对计算方法做了改进,引入了“关联度”的概念;马腾(2015:201)详细解说:两个点(基元)之间关联度的计算公式为“兼有数/总数”,其中,点A、B的兼有数指A、B的共现次数;而点A、B的总数指A、B各自出现次数之和,再减去它们的共现次数。 不过,这一计算仍然存在很大的问题,在郭锐(2012b)的计算中,“12-13”之间的关联度仍高到59.54%,排名第五,比排名第六的“1-13”的31.48%高出不少;而在马腾(2015:202)中,“12-13”的兼有数被从郭锐(2015:169)中的“181次”一下下降到了“2次”,但却未说明原因。