云南省图书馆机构用户,欢迎您!
肌动理论(Motor theory)是关于语音感知的一种理论,它认为听者是根据自己的发音动作来匹配和感知外来语音的。这一理论刚提出就在学术界充满争议。本文利用脑科学和神经科学的最新研究成果来支持语音感知的肌动理论,并进一步说明:1)听者的语音感知机制和发音机制紧密相关;2)与其它非语音的声音感知不同,语音感知带有很强的主观性,而这种主观性受特定语言规则的制约;3)人类就是通过这种主观的语音感知来过滤各种语音变异,达到语言交际的目标;4)电脑语音识别必须转变思路,要充分考虑人类语音感知的特点,这样才能提高语音识别率。
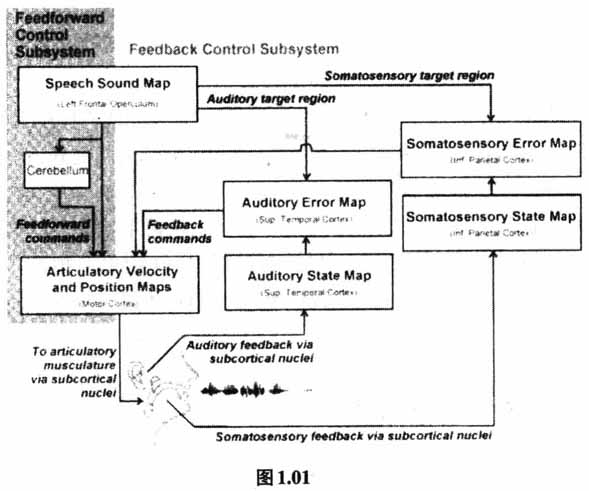 语音反馈刺激对语音发声具有的作用在聋哑人语言教学中得到充分体现。中国俗话有“十聋九哑”之说,就是说绝大多数耳聋的都是不能说话的哑巴。其实哑巴的发音器官没有任何缺陷,不会说话是因为耳聋,听不到语音,没有言语的刺激。19世纪中叶Alexander Melville Bell[1]了解到这一点,为聋哑人设计一套“可视语言”(Visible Speech),他根据发音的解剖生理构造把每个音(元音或辅音)画成可视的发音图,让聋哑人看图发音,可是Bell没有认识到语音反馈在语音发音中的重要性,所以这种对聋哑人的发音教学是失败的。即使是正常人,如果在没有言语环境中生长,过了言语习得的最佳时机(critical period/sensitive period),以后说话的能力就会大打折扣。道理很简单:因为听不见,所以说不出。可见,言语发声与言语感知有十分密切的关系。既然语言中说和听有这么密切的关系,那么,是不是可以反之亦然,即:因为说不出,所以听不见?这个命题使人想起语音感知的“肌动理论”(motor theories)。 肌动理论的最早版本叫analysis-by-synthesis theory,上世纪50年代末由麻省理工学院著名教授Kenneth N.Stevens和Morris Halle[5]提出。他们认为听者是根据自己的发音来分析和感知外来的语音信号的。Haskins实验室的科学家Alvin M.Liberman等人[6]也在差不多的时间正式提出Motor theory这个名称,以后Liberman等人[7]对Motor theory又做了重大修改。基于语音感知和声学特征缺乏一致性(lack of invariance)、语音声学信号的不可切割性(nonsegmentability),以及语音传送信息的相对高效性(the relatively high efficiency of transmission of information),他们也认为听者“雇佣”自己声腔大小的信息以及自己的发音运动特性,直接对外来语音作出分析和解码。Stevens和Halle提出的analysis-by-synthesis theory和Liberman等人提出的Motor theory都强调听者是根据自己的发音动作来对外来语音解码和感知的。
语音反馈刺激对语音发声具有的作用在聋哑人语言教学中得到充分体现。中国俗话有“十聋九哑”之说,就是说绝大多数耳聋的都是不能说话的哑巴。其实哑巴的发音器官没有任何缺陷,不会说话是因为耳聋,听不到语音,没有言语的刺激。19世纪中叶Alexander Melville Bell[1]了解到这一点,为聋哑人设计一套“可视语言”(Visible Speech),他根据发音的解剖生理构造把每个音(元音或辅音)画成可视的发音图,让聋哑人看图发音,可是Bell没有认识到语音反馈在语音发音中的重要性,所以这种对聋哑人的发音教学是失败的。即使是正常人,如果在没有言语环境中生长,过了言语习得的最佳时机(critical period/sensitive period),以后说话的能力就会大打折扣。道理很简单:因为听不见,所以说不出。可见,言语发声与言语感知有十分密切的关系。既然语言中说和听有这么密切的关系,那么,是不是可以反之亦然,即:因为说不出,所以听不见?这个命题使人想起语音感知的“肌动理论”(motor theories)。 肌动理论的最早版本叫analysis-by-synthesis theory,上世纪50年代末由麻省理工学院著名教授Kenneth N.Stevens和Morris Halle[5]提出。他们认为听者是根据自己的发音来分析和感知外来的语音信号的。Haskins实验室的科学家Alvin M.Liberman等人[6]也在差不多的时间正式提出Motor theory这个名称,以后Liberman等人[7]对Motor theory又做了重大修改。基于语音感知和声学特征缺乏一致性(lack of invariance)、语音声学信号的不可切割性(nonsegmentability),以及语音传送信息的相对高效性(the relatively high efficiency of transmission of information),他们也认为听者“雇佣”自己声腔大小的信息以及自己的发音运动特性,直接对外来语音作出分析和解码。Stevens和Halle提出的analysis-by-synthesis theory和Liberman等人提出的Motor theory都强调听者是根据自己的发音动作来对外来语音解码和感知的。