历时语料可对各年代语言样本进行比较,发现语言运用的历时变化,为翻译研究、语言演化研究及翻译语言与目标语之间的互动提供数据支持。本文探讨历时语料库的研制意义、研制思路,并报告我们在历时类比语料库研制上的进展。 1.研制历时语料库的意义 研究语言变化有多种路径,如语言生态学、类型学、社会学和语言接触(Hurford et al.1998;Hichey 2003)。翻译属于语言接触,但在有关语言变化的文献里,它不是关键词。事实上,在特定历史时期,翻译与目标语的演化关系密切:文艺复兴时期,德国宗教领袖马丁·路德通过《圣经》翻译促成德语新文体产生;法国的安岳借助翻译改良、丰富了法语(王克非1997)。在中国,近代汉语受佛经翻译影响演化出白话新文体(梁晓虹1992);在二十世纪,现代汉语白话文受翻译语言推动而走向成熟,同时它又制约翻译语言的变化范围。二者如何相互影响?背后的动因是什么?这些问题需要通过梳理大量语料来回答。 根据王力(1943/1985),“五四”以后,汉语受西洋语法影响,经历了巨大变化,主要表现在特定词性和句式的使用频率、句法形式严密化,以及分句位置的变化上。长期以来,对汉语欧化的判断主要依赖研究者的自然语感(朱一凡2011),研究的素材来源不够丰富,考察范围有限,研究的深度和广度受到严重制约;另外,汉语本身对翻译语言的制约作用并没有引起足够重视,因此二者间存在的动态互动关系需要从历时语料数据中加以观测和分析。 2.国内外历时语料库的创建 研究语言变化需要历时语言素材。在欧美,能满足这一需求的历时语料库(又称动态语料库)近来发展迅速。在上世纪九十年代,出现了许多借助语料库研究历时新闻语料的语言研究项目,有不少历时语料库在这一时期建立,如Zurich English Newspaper Corpus,Rostock Newspaper Corpus和Lampeter Corpus(Studer 2008:3)。根据Renouf(2007),历时语料库在西方也不过二十年的时间。1990年,第一个历时语料库AVIATOR由伯明翰大学研制成功(同期还有著名的The Helsinki Corpus of English Texts),另一个历时语料库ACRONYM于1994年建成。以上两个库都使用连续出版的报刊为语料,但目前还有代表性更强、跨度长达300多年的ARCHER平衡英语语料库,以及建设中的4亿词的COHA(美国英语历史语料库)。当然,有些共时语料库本身具有历时特征,如COCA收集了1990-2012年间的当代美国英语语料,语料文本按文体收集(口语、小说、普通杂志、报纸和学术期刊),五类文体的比例平均,各占20%,体现了平衡性(Davies2009);该库在以每年两千万词的幅度增加,库容目前已达到4.5亿词。这种跟踪性的语料库(monitor cor-pus)长期做下去,自然就是历时语料,同时又能保证把某段时期(如10年)的语料提取出来作为共时语料库研究。同样,TIME Magazine Corpus of American English(1923-2006)收集了《时代》杂志的文本,也是观察语言历时变化的上好平台。 利用网络挖掘历史文本资源建设历时语料检索平台既方便又经济。在这方面,已经有人在使用“谷歌图书”(Google book)作为在线资源库实施词丛(ngram)检索①。可用于检索的图书动辄百万本,库容少说也有四五百亿词,检索规模和时间跨度(1500s至今)可谓壮观,其应用前景值得期待。 历时语料库在设计上除了考虑共时语料要注意的平衡性和代表性,还要特别重视时间(包括年份和年代),历时语料的检索可以呈现某个词在每个年代的使用频次和频率,如:
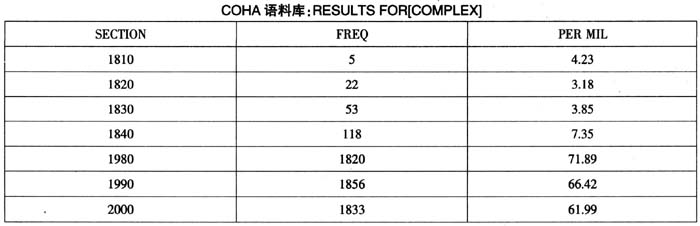
也可以呈现该词在每个年份的使用频次和频率,如:
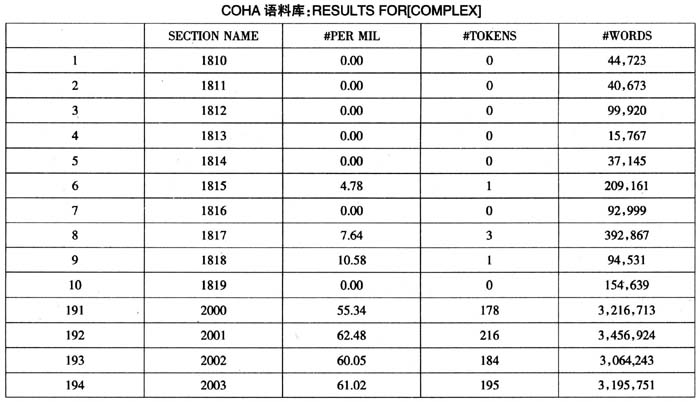
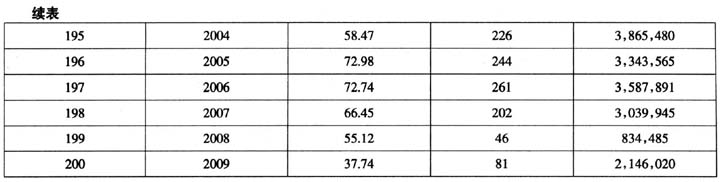
在中国,使用历时语言素材进行研究有悠久传统,但多以整书做素材,取材范围有限。自上世纪八九十年代,我国开始创建汉语语料库。到目前为止,汉语语料库的创建主体是共时语料,如台湾“‘中研院’平衡语料库”,北京大学“CCL语料库”。后者虽然包含古代汉语和现代汉语,但检索不支持按年代或年份检索。有报告显示,Tsou et al.(2011)在建设LIVAC汉语语料库②,该库收集了4亿汉字的新闻语料,语料时间范围是1995-2011,跨度达16年,来自北京、香港、新加坡、上海、台湾、澳门等多个有代表性的区域性语言社团。该库可以检索到某个词汇在某个时间段使用的地域分布状况,支持语言的同质、异质研究,以及共时和历时研究。 从以上情况看,汉语语料库建设尽管发展迅速,但还没有真正意义上的汉语平衡历时语料库。汉语历时语料的收集和检索近些年来受到重视,如北京外国语大学研制的通用汉英对应语料库有长达一个世纪的英汉双向历时翻译语料,但语料的历时分布还不够均匀,需要进行适当补充后再用于历时类比研究。 基于历时类比语料的语言研究方兴未艾,建立抽样合理、规范的现代汉语历时语料库很有必要。国家社科基金重大招标项目“大规模英汉平行语料库的建立与加工”将建设历时语料库视为基础工作,试图为翻译与现代汉语之间的互动建立比较完整的描写和分析框架,使多层面、系统性的翻译和语言变化历时研究成为可能。