云南省图书馆机构用户,欢迎您!
本文采用向心理论的参数化研究方法,根据影响前瞻中心排序的一些主要因素设计了6种算法,对比分析了不同排序方法对英汉指代消解的影响。研究发现,整体而言:1)语法功能在两种语言中都比线性语序更准确地反映了前瞻中心显著度;2)在按语法功能排序的基础上,考虑语法功能平行性对英汉零形代词消解具有一定优势,考虑回指中心连贯性对英汉代词消解具有一定优势,同时考虑两者的算法具有更广泛的优势;3)按语法功能排序,并同时考虑语法功能平行性和句子层级结构,对英汉零形代词和汉语代词消解都可以获得最佳结果,而对英语代词消解却会产生消极的影响。
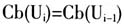 的倾向,即语篇实体的连贯性因素;5)Alg5在Alg2基础上同时考虑了语法功能的平行性和语篇实体连贯性这两个因素;6)Alg6在Alg3基础上进一步考虑了主句中的回指语倾向于回指前一主句中提及的语篇实体,即语句的层级结构这一因素。我们将每次运作的结果读入数据库,与数据库中人工标注的回指信息进行自动比对,从而检验在不同参数设定的情况下指代消解的有效性。 3.数据分析 上述6种算法在对语句做两种不同定义的情况下(U1表示将语句设定为小句,U2表示将语句设定为自然句,详见许余龙等2008;孙珊珊等2013),对英汉民间故事和儿童故事两类语料中出现的两种指代词,即零形代词(ZP)和代词(PRON)的整体消解结果见表1(其中的数值为百分比,代表消解准确率)。
的倾向,即语篇实体的连贯性因素;5)Alg5在Alg2基础上同时考虑了语法功能的平行性和语篇实体连贯性这两个因素;6)Alg6在Alg3基础上进一步考虑了主句中的回指语倾向于回指前一主句中提及的语篇实体,即语句的层级结构这一因素。我们将每次运作的结果读入数据库,与数据库中人工标注的回指信息进行自动比对,从而检验在不同参数设定的情况下指代消解的有效性。 3.数据分析 上述6种算法在对语句做两种不同定义的情况下(U1表示将语句设定为小句,U2表示将语句设定为自然句,详见许余龙等2008;孙珊珊等2013),对英汉民间故事和儿童故事两类语料中出现的两种指代词,即零形代词(ZP)和代词(PRON)的整体消解结果见表1(其中的数值为百分比,代表消解准确率)。 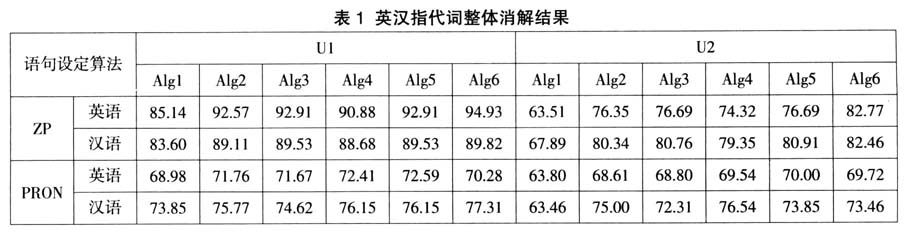 表1显示,无论在汉语还是英语中,Alg2的消解结果都明显好于Alg1。这说明,整体而言,在英汉两种语言中,前瞻中心按语法功能排序,要比按线性语序排序更准确地体现语篇实体的显著度。而对于零形代词和代词的消解,两种语言则既呈现出某些相似性,又有一些差异。消解零形代词的最佳算法,无论在哪种语言中都是Alg6,其次为Alg5和Alg3;消解代词的最佳算法,在英语中是Alg5,而在汉语中是Alg6和Alg4。得出这样的结果并不是偶然的,下面我们将结合具体例子进行分析。
表1显示,无论在汉语还是英语中,Alg2的消解结果都明显好于Alg1。这说明,整体而言,在英汉两种语言中,前瞻中心按语法功能排序,要比按线性语序排序更准确地体现语篇实体的显著度。而对于零形代词和代词的消解,两种语言则既呈现出某些相似性,又有一些差异。消解零形代词的最佳算法,无论在哪种语言中都是Alg6,其次为Alg5和Alg3;消解代词的最佳算法,在英语中是Alg5,而在汉语中是Alg6和Alg4。得出这样的结果并不是偶然的,下面我们将结合具体例子进行分析。