云南省图书馆机构用户,欢迎您!
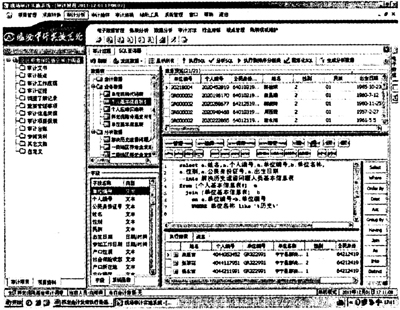
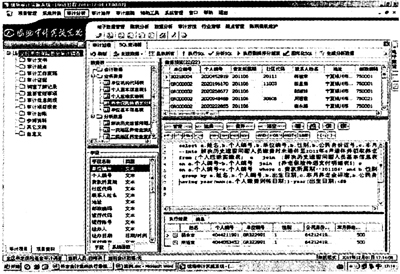
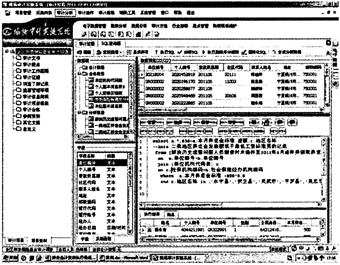 select a.姓名,a.个人编号,a.单位编号,b.单位名称,a.性别,a.公民身份证号,a.出生日期 into解决历史遗留问题人员基本信息表from[个人基本信息表]a join[单位基本信息表]b on a.单位编号=b.单位编号WHERE单位名称like‘%历史%’ 第四步:将[个人应缴实缴表]、[解决历史遗留问题人员基本信息表]和[基本养老保险待遇支付明细信息表实例]连接,生成[解决历史遗留问题人员缴费时未退休至2011年6月退休并领取养老金性别为男的人员情况表]。 select a.姓名,b.个人编号,b.单位编号,b.性别,b.公民身份证号,c.本月养老金标准 into解决历史遗留问题人员缴费时未退休至2011年6月退休并领取养老金性别为男的人员情况表from[个人应缴实缴表]a join[解决历史遗留问题人员基本信息表]b on a.个人编号=b.个人编号join[养老保险待遇支付明细表]c on a.个人编号=c.个人编号where c.费款所属期=‘201106’and b.性别=‘1’ group by a.姓名,b.个人编号,b.出生日期,c.本月养老金标准,b.公民身份证号,b.性别.,b.单位编号having year(max(a.个人缴费到账日期))-year(出生日期)<60 (注:性别为女的人员只需将条件设置个人缴费到账日期-出生日期<55) 第五步:筛选一、二、三类地区养老金发放额低于最低工资标准性别为男的记录。 select a.*,656-a.本月养老金标准差额,c.地区名称 into X类地区养老金发放额低于最低工资标准男的记录 from[解决历史遗留问题人员缴费时未退休至2011年6月退休并领取养老金性别为男的人员情况表]a join[单位基本信息表]b on a.单位编号=b.单位编号 join[单位机构代码表]c on c.社保机构编码=b.社会保险经办机构编码 where a.本月养老金标准<820*0.8 and c.地区名称in(‘XX县’,‘XX县’,‘XX市’) 最终查出:以2011年6月为例,全区存在600多人养老金的发放金额低于最低工资标准的80%问题,随着解决历史遗留问题此类退休人员增多,涉及人数还将不断上升。由于这一问题涉及到低收入群体的切身利益和社会公平问题,自治区社保局高度重视,将提请自治区人社厅进一步明确政策规定,制定相关计发办法,使政策更趋于合理、公平,使惠民政策落到实处。
select a.姓名,a.个人编号,a.单位编号,b.单位名称,a.性别,a.公民身份证号,a.出生日期 into解决历史遗留问题人员基本信息表from[个人基本信息表]a join[单位基本信息表]b on a.单位编号=b.单位编号WHERE单位名称like‘%历史%’ 第四步:将[个人应缴实缴表]、[解决历史遗留问题人员基本信息表]和[基本养老保险待遇支付明细信息表实例]连接,生成[解决历史遗留问题人员缴费时未退休至2011年6月退休并领取养老金性别为男的人员情况表]。 select a.姓名,b.个人编号,b.单位编号,b.性别,b.公民身份证号,c.本月养老金标准 into解决历史遗留问题人员缴费时未退休至2011年6月退休并领取养老金性别为男的人员情况表from[个人应缴实缴表]a join[解决历史遗留问题人员基本信息表]b on a.个人编号=b.个人编号join[养老保险待遇支付明细表]c on a.个人编号=c.个人编号where c.费款所属期=‘201106’and b.性别=‘1’ group by a.姓名,b.个人编号,b.出生日期,c.本月养老金标准,b.公民身份证号,b.性别.,b.单位编号having year(max(a.个人缴费到账日期))-year(出生日期)<60 (注:性别为女的人员只需将条件设置个人缴费到账日期-出生日期<55) 第五步:筛选一、二、三类地区养老金发放额低于最低工资标准性别为男的记录。 select a.*,656-a.本月养老金标准差额,c.地区名称 into X类地区养老金发放额低于最低工资标准男的记录 from[解决历史遗留问题人员缴费时未退休至2011年6月退休并领取养老金性别为男的人员情况表]a join[单位基本信息表]b on a.单位编号=b.单位编号 join[单位机构代码表]c on c.社保机构编码=b.社会保险经办机构编码 where a.本月养老金标准<820*0.8 and c.地区名称in(‘XX县’,‘XX县’,‘XX市’) 最终查出:以2011年6月为例,全区存在600多人养老金的发放金额低于最低工资标准的80%问题,随着解决历史遗留问题此类退休人员增多,涉及人数还将不断上升。由于这一问题涉及到低收入群体的切身利益和社会公平问题,自治区社保局高度重视,将提请自治区人社厅进一步明确政策规定,制定相关计发办法,使政策更趋于合理、公平,使惠民政策落到实处。