云南省图书馆机构用户,欢迎您!
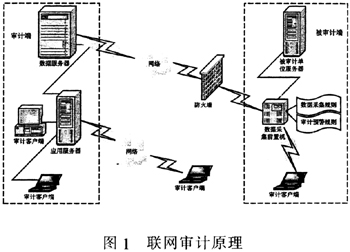 我国目前正在大力开展联网审计项目的应用,如财政联网审计项目、地税联网审计项目、海关联网审计项目等,因此,研究联网审计数据采集过程中的审计预警方法对实施联网审计具有重要的理论和实践价值。 二、审计预警模型的原理 联网审计中的审计预警是一个定时触发的审计预查系统,它被部署在被审计单位端的审计数据采集服务器中,该服务器被称为审计数据采集前置机。审计预警模型包括审计预审系统和预审结果报告系统两部分。在联网审计数据采集系统把被审计单位的财务和业务数据采集到审计前置机(托管服务器)的过程中,系统自动启动审计预审系统,利用审计专家系统提供的计算机审计分析指标和可执行方法(预警规则)进行数据分析过滤,把有问题的数据筛选出来。在审计预审系统执行完毕后,审计告警系统自动启动,告知审计人员本次发现的有问题的数据,便于审计人员进行职业分析判断和进一步的延伸审计。 另外,审计预警模型除了需要把不符合业务规则的数据预审出来之外,还需要检测被审计数据中不完整数据的情况,以便审计人员进行决策。因此,检测所采集数据的完整性也是审计预警的一个重要功能。 审计预警主要包括审计预审和预审结果报告两个功能。审计预审功能是系统对采集转换后的审计账表数据按照预先设置的预警规则和计算机审计方法进行批量自动审核分析,将发现的审计疑点存于审计疑点数据库中。预审结果报告则是系统将审计疑点和更改疑点的数据存效到预审结果报告数据库中,并向审计人员发出预审结果报告。 根据以上分析,本文把业务规则和不完整数据检测应用于审计预警之中,提出一种用于联网审计的审计预警方法,如图2所示,其原理如下。 1.根据对被审计单位的业务及数据库系统的分析,在规则库定义相应的业务规则。 2.根据预定义的数据采集规则,把被审计数据采集到前置机中。 3.启动基于业务规则的审计预警。在审计预警过程中,对于采集的每条记录,规则库检索模块检索库中的审计业务规则,并据此对每条记录进行检测,内容包括:根据字段的域值来检测一条数据的每个字段;根据同一数据中字段之间的关联关系来进行检测,比如采取函数依赖关系等对每条数据的多个字段进行关联检测。通过以上过程可以判定每条记录是否符合所定义的业务规则,如果记录不符合所定义的业务规则,则将该记录导入前置机系统中的异常数据库。
我国目前正在大力开展联网审计项目的应用,如财政联网审计项目、地税联网审计项目、海关联网审计项目等,因此,研究联网审计数据采集过程中的审计预警方法对实施联网审计具有重要的理论和实践价值。 二、审计预警模型的原理 联网审计中的审计预警是一个定时触发的审计预查系统,它被部署在被审计单位端的审计数据采集服务器中,该服务器被称为审计数据采集前置机。审计预警模型包括审计预审系统和预审结果报告系统两部分。在联网审计数据采集系统把被审计单位的财务和业务数据采集到审计前置机(托管服务器)的过程中,系统自动启动审计预审系统,利用审计专家系统提供的计算机审计分析指标和可执行方法(预警规则)进行数据分析过滤,把有问题的数据筛选出来。在审计预审系统执行完毕后,审计告警系统自动启动,告知审计人员本次发现的有问题的数据,便于审计人员进行职业分析判断和进一步的延伸审计。 另外,审计预警模型除了需要把不符合业务规则的数据预审出来之外,还需要检测被审计数据中不完整数据的情况,以便审计人员进行决策。因此,检测所采集数据的完整性也是审计预警的一个重要功能。 审计预警主要包括审计预审和预审结果报告两个功能。审计预审功能是系统对采集转换后的审计账表数据按照预先设置的预警规则和计算机审计方法进行批量自动审核分析,将发现的审计疑点存于审计疑点数据库中。预审结果报告则是系统将审计疑点和更改疑点的数据存效到预审结果报告数据库中,并向审计人员发出预审结果报告。 根据以上分析,本文把业务规则和不完整数据检测应用于审计预警之中,提出一种用于联网审计的审计预警方法,如图2所示,其原理如下。 1.根据对被审计单位的业务及数据库系统的分析,在规则库定义相应的业务规则。 2.根据预定义的数据采集规则,把被审计数据采集到前置机中。 3.启动基于业务规则的审计预警。在审计预警过程中,对于采集的每条记录,规则库检索模块检索库中的审计业务规则,并据此对每条记录进行检测,内容包括:根据字段的域值来检测一条数据的每个字段;根据同一数据中字段之间的关联关系来进行检测,比如采取函数依赖关系等对每条数据的多个字段进行关联检测。通过以上过程可以判定每条记录是否符合所定义的业务规则,如果记录不符合所定义的业务规则,则将该记录导入前置机系统中的异常数据库。 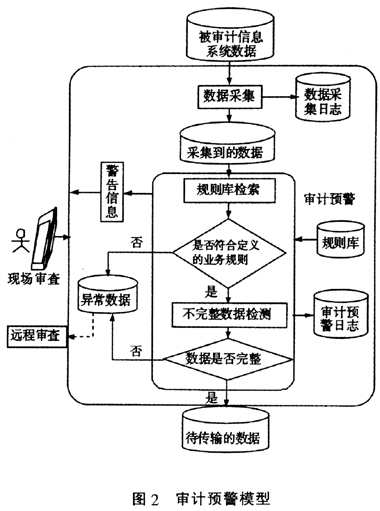 4.启动不完整数据检测。根据定义的不完整数据检测方法,系统对采集来的数据进行检测,并把检测出的不完整数据导入前置机系统中的异常数据库。 5.异常数据库中的异常数据可以存放在前置机系统中,也可以通过网络传输到审计单位,审计人员可以实时或定期地对这些异常数据进行现场或非现场审查。 三、审计预警模型的关键技术分析 (一)规则库 从图2我们可以看出,规则库是审计预警模型的核心。规则库用来存放用于审计预警的业务规则和不完整数据检测规则,主要包括八个方面。 第一,业务规则。业务规则是指符合被审计单位业务的某一数值范围,一个有效数值的集合,或者是指某一种数据模式。业务规则根据其规则内容,可分成通用业务规则和特殊业务规则。 第二,不完整识别规则。它用来指定一条记录为不完整数据的条件,比如记录中字段值缺失比率的阈值。
4.启动不完整数据检测。根据定义的不完整数据检测方法,系统对采集来的数据进行检测,并把检测出的不完整数据导入前置机系统中的异常数据库。 5.异常数据库中的异常数据可以存放在前置机系统中,也可以通过网络传输到审计单位,审计人员可以实时或定期地对这些异常数据进行现场或非现场审查。 三、审计预警模型的关键技术分析 (一)规则库 从图2我们可以看出,规则库是审计预警模型的核心。规则库用来存放用于审计预警的业务规则和不完整数据检测规则,主要包括八个方面。 第一,业务规则。业务规则是指符合被审计单位业务的某一数值范围,一个有效数值的集合,或者是指某一种数据模式。业务规则根据其规则内容,可分成通用业务规则和特殊业务规则。 第二,不完整识别规则。它用来指定一条记录为不完整数据的条件,比如记录中字段值缺失比率的阈值。