云南省图书馆机构用户,欢迎您!
关于动词过去时的规则形式和不规则形式习得、表征和处理过程的争论持续了20多年,并且吸引了语言学家、心理学家、神经科学家、计算机学家等的关注。本文回顾了双方争论的来龙去脉,讨论了双方争论的三大焦点问题,即语言处理需要规则还是联结,规则形式和不规则形式的处理是由相同的心理机制还是两个不同的心理机制来完成的,究竟应该将大脑视为模块的符号处理系统还是多元的人工神经网络。这场争论的意义在于通过对过去时表征和加工过程的研究来发现语言甚至心智的运作过程,检验认知科学中传统的符号主义和新兴的联结主义。
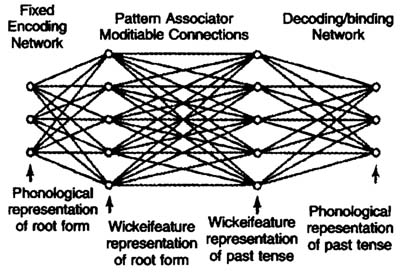 图1 RM模型的基本结构[2:222] Rumelhart & McClelland[2]提出了不同的观点,他们认为规则在语言的习得与处理过程中并没有起到作用,Chomsky所提出的规则系统只能够用于描述语言本身,并不能够用于描述语言习得与处理的过程。鉴于此,他们认为联结主义的模型更加适合解释语言习得的过程,儿童是在大量接触语言的基础上,建立起动词词根的语音特征与过去时形式的语音特征之间的联结,并通过调整动词词根和过去时形式之间联结权重的方式来习得动词的过去时态。无论是规则的过去时形式,还是不规则过去时形式的产生均不需要规则,只需要基于与已知动词语音上的相似性即可以产生。图1即是Rumelhart和McClelland[2]在1986年提出的用来模拟英语动词过去时习得过程的RM模型。该模型为单向输入,并没有对规则的表征,只包含相互联结的类似于神经细胞的单元。如图1所示(自左向右),RM模型包括三个组成部分。第一部分是一个固定的编码网络,负责把输入的动词词根的语音表征转化为Wickel特征表征,即把词汇的语音形式表征为一系列的音位单元,其中每个音位单元由某个特定的音素及与该音素紧邻的前一个和后一个音素组成。例如;help就可以被表征为_he,hel,elp和lp_。第二个部分是整个系统的关键,由一个可调节的模式联结器(patternassociator)组成,负责完成从动词词根的语音形式到与其相应的过去时的语音形式之间的映射,所有的学习和训练过程主要是由这个部分来完成的。第三部分是一个解码网络,负责把过去时形式的Wickel特征表征解码为其语音表征。这个模型的训练采用了Rosenblatt[13]的感知合并程序(perception convergence procedure)。在训练这个模型时,研究人员会将某个动词的词根及其正确的过去时形式输入到模型中。该模型首先对词根进行编码,然后计算输出单元中Wickel特征表征的激活值,最后将这个值与该动词相对应的正确过去时形式的激活值进行比较。如果计算出的激活值与正确的值相匹配,就说明相关联结之间的权重值合理,不需要进一步学习。相反,如果一个应该被激活的单元没有被激活,相关联结之间的权重值就会相应增强,激活阈值也会相应地降低。同样的,如果一个不该被激活的单元被激活了,那么就要相应地降低相关联结的权重值,激活阈值则会相应提高。这样,整个系统经过大量的训练(即学习的过程)就可以逐渐掌握词根和它们的过去时形式之间的联结权重,从而模拟儿童习得语言的过程。RM模型是一个经典的联结主义模型,随后的联结主义网络模型采用了“反馈学习法”(back-propagation method),在模型中加入了隐藏节点,进一步提高了模型的性能。
图1 RM模型的基本结构[2:222] Rumelhart & McClelland[2]提出了不同的观点,他们认为规则在语言的习得与处理过程中并没有起到作用,Chomsky所提出的规则系统只能够用于描述语言本身,并不能够用于描述语言习得与处理的过程。鉴于此,他们认为联结主义的模型更加适合解释语言习得的过程,儿童是在大量接触语言的基础上,建立起动词词根的语音特征与过去时形式的语音特征之间的联结,并通过调整动词词根和过去时形式之间联结权重的方式来习得动词的过去时态。无论是规则的过去时形式,还是不规则过去时形式的产生均不需要规则,只需要基于与已知动词语音上的相似性即可以产生。图1即是Rumelhart和McClelland[2]在1986年提出的用来模拟英语动词过去时习得过程的RM模型。该模型为单向输入,并没有对规则的表征,只包含相互联结的类似于神经细胞的单元。如图1所示(自左向右),RM模型包括三个组成部分。第一部分是一个固定的编码网络,负责把输入的动词词根的语音表征转化为Wickel特征表征,即把词汇的语音形式表征为一系列的音位单元,其中每个音位单元由某个特定的音素及与该音素紧邻的前一个和后一个音素组成。例如;help就可以被表征为_he,hel,elp和lp_。第二个部分是整个系统的关键,由一个可调节的模式联结器(patternassociator)组成,负责完成从动词词根的语音形式到与其相应的过去时的语音形式之间的映射,所有的学习和训练过程主要是由这个部分来完成的。第三部分是一个解码网络,负责把过去时形式的Wickel特征表征解码为其语音表征。这个模型的训练采用了Rosenblatt[13]的感知合并程序(perception convergence procedure)。在训练这个模型时,研究人员会将某个动词的词根及其正确的过去时形式输入到模型中。该模型首先对词根进行编码,然后计算输出单元中Wickel特征表征的激活值,最后将这个值与该动词相对应的正确过去时形式的激活值进行比较。如果计算出的激活值与正确的值相匹配,就说明相关联结之间的权重值合理,不需要进一步学习。相反,如果一个应该被激活的单元没有被激活,相关联结之间的权重值就会相应增强,激活阈值也会相应地降低。同样的,如果一个不该被激活的单元被激活了,那么就要相应地降低相关联结的权重值,激活阈值则会相应提高。这样,整个系统经过大量的训练(即学习的过程)就可以逐渐掌握词根和它们的过去时形式之间的联结权重,从而模拟儿童习得语言的过程。RM模型是一个经典的联结主义模型,随后的联结主义网络模型采用了“反馈学习法”(back-propagation method),在模型中加入了隐藏节点,进一步提高了模型的性能。