云南省图书馆机构用户,欢迎您!
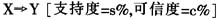 其中
其中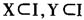 ,并且
,并且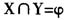 ,I为项目集,事务集D中的每个事务都是项目集I的子集。如果包含X的事务中c%同时包含Y,我们说规则
,I为项目集,事务集D中的每个事务都是项目集I的子集。如果包含X的事务中c%同时包含Y,我们说规则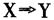 的可信度为c%。如果D中s%的事务包含X∪Y,我们说规则的支持度为s%。一个典型的关联规则实例是“80%购买面包的顾客同时也会购买牛奶”,最为著名的关联规则发现方法是R.Agrawal提出的Apriori算法。关联分析广泛应用于市场营销、事务分析等应用领域。 2.分类和预测 分类的目的就是找出一个分类函数或分类模型(分类器),该模型能把数据库中的数据项映射到给定类别中的某一个。分类和回归都可用于预测,不同的是,分类的输出是离散的类别值,而回归的输出则是连续数值。 要构造分类器,需要有一个训练样本数据集作为输入,训练集中每个元组的类别已知。分类挖掘算法可以对已有的分类进行归纳,即从训练样本数据中学习,从而建立分类模型。再根据已知的分类规则,预测未知数据实例的类别。 3.聚类 聚类分析是将数据对象分成几类,使得各类内部数据对象间的相似度最大,而各类间对象的相似度最小。聚类分析与分类预测方法的明显不同之处在于,分类预测获取模型所使用的训练数据其类别是已知的,属于有指导的学习方法;而聚类分析所分析和处理的数据均是无类别标签的,属于无指导的学习方法。通过聚类,可以发现数据的整个分布情况,以及数据属性之间所存在的有趣的、有价值的相关联系。 4.孤立点挖掘 数据库中可能包含一些数据对象,它们与数据的一般行为或模型不一致。这些数据对象是孤立点(又叫离群)。大部分数据挖掘方法将孤立点视为噪声或异常而丢弃。然而,在一些应用中(如欺骗检测、审计),异常的事件可能比正常出现的那些更令人关注。 (二)数据挖掘在审计中的应用 1.关联分析 在财务数据或经济数据中,同类或不同类会计科目及数据项之间可能存在某种对应关系,通过挖掘算法(如Apriori算法),按照非财务逻辑关系的规律来挖掘,可发现一些隐藏的经济活动规律,这些被挖掘出来的关联规则,可以用来丰富审计知识库,为审计人员的进一步工作提供参考。 通过对以往审计过的企业大量历史数据进行挖掘,以建立审计特征行为模板。当发现同类企业(含该企业)近期数据挖掘结果与该模板偏离较大时,可以根据挖掘结果重点审计。如通过数据挖掘技术,可以发现一个单位的车辆数和养路费、汽车保险费等日常维护支出存在一定的关联,当这个关系异于常值时,也许能据此发现是否存在用账外资产买车的行为,进而查出“小金库”问题。 另一方面,通过对审计出重大问题的企业财务数据进行挖掘,得到可以引导发现问题的关联规则,同样可以用来丰富审计知识库。比如,有学者曾对2003年至2006年受到证监会处罚的66家上市公司的财务数据进行挖掘,得到不少“有趣”的关联规则,如“连续两年亏损,第三年经营业绩又没有得到根本改善的上市公司,有80%的可能存在财务舞弊”。 2.分类 某种意义上讲,审计的部分工作就是对被审计单位进行分类,只不过通常只需要简单的分成两个类:有财务舞弊和无财务舞弊。因此可以应用现已开发出来的分类算法进行辅助审计。分类挖掘的重点是特征选取、选择训练样本和分类器。 特征选择是模型进行计算的基础,指标变量选择的好坏直接影响到挖掘结果的质量。国内外已有很多关于这方面的文献可供参考,一般可选择下列指标: (1)盈利能力指标 包括总资产净利润率、资产报酬率、净资产收益率、营业收入净利润率、每股收益、营业毛利率、股东权益净利润率等。 (2)结构性指标 包括资产负债率、固定资产比率、营运资金对资产总额比率、应收账款占主营业务收入比重、营业利润比重、产权比率等。例如签订销售合同物权尚未转移时确认收入或者将库存商品确认为主营业务收入,同时增加应收账款,使主营业务收入虚增,形成白条利润,同时又通过应收账款虚增了资产,这样会造成应收账款占主营业务收入的比重发生异常。
的可信度为c%。如果D中s%的事务包含X∪Y,我们说规则的支持度为s%。一个典型的关联规则实例是“80%购买面包的顾客同时也会购买牛奶”,最为著名的关联规则发现方法是R.Agrawal提出的Apriori算法。关联分析广泛应用于市场营销、事务分析等应用领域。 2.分类和预测 分类的目的就是找出一个分类函数或分类模型(分类器),该模型能把数据库中的数据项映射到给定类别中的某一个。分类和回归都可用于预测,不同的是,分类的输出是离散的类别值,而回归的输出则是连续数值。 要构造分类器,需要有一个训练样本数据集作为输入,训练集中每个元组的类别已知。分类挖掘算法可以对已有的分类进行归纳,即从训练样本数据中学习,从而建立分类模型。再根据已知的分类规则,预测未知数据实例的类别。 3.聚类 聚类分析是将数据对象分成几类,使得各类内部数据对象间的相似度最大,而各类间对象的相似度最小。聚类分析与分类预测方法的明显不同之处在于,分类预测获取模型所使用的训练数据其类别是已知的,属于有指导的学习方法;而聚类分析所分析和处理的数据均是无类别标签的,属于无指导的学习方法。通过聚类,可以发现数据的整个分布情况,以及数据属性之间所存在的有趣的、有价值的相关联系。 4.孤立点挖掘 数据库中可能包含一些数据对象,它们与数据的一般行为或模型不一致。这些数据对象是孤立点(又叫离群)。大部分数据挖掘方法将孤立点视为噪声或异常而丢弃。然而,在一些应用中(如欺骗检测、审计),异常的事件可能比正常出现的那些更令人关注。 (二)数据挖掘在审计中的应用 1.关联分析 在财务数据或经济数据中,同类或不同类会计科目及数据项之间可能存在某种对应关系,通过挖掘算法(如Apriori算法),按照非财务逻辑关系的规律来挖掘,可发现一些隐藏的经济活动规律,这些被挖掘出来的关联规则,可以用来丰富审计知识库,为审计人员的进一步工作提供参考。 通过对以往审计过的企业大量历史数据进行挖掘,以建立审计特征行为模板。当发现同类企业(含该企业)近期数据挖掘结果与该模板偏离较大时,可以根据挖掘结果重点审计。如通过数据挖掘技术,可以发现一个单位的车辆数和养路费、汽车保险费等日常维护支出存在一定的关联,当这个关系异于常值时,也许能据此发现是否存在用账外资产买车的行为,进而查出“小金库”问题。 另一方面,通过对审计出重大问题的企业财务数据进行挖掘,得到可以引导发现问题的关联规则,同样可以用来丰富审计知识库。比如,有学者曾对2003年至2006年受到证监会处罚的66家上市公司的财务数据进行挖掘,得到不少“有趣”的关联规则,如“连续两年亏损,第三年经营业绩又没有得到根本改善的上市公司,有80%的可能存在财务舞弊”。 2.分类 某种意义上讲,审计的部分工作就是对被审计单位进行分类,只不过通常只需要简单的分成两个类:有财务舞弊和无财务舞弊。因此可以应用现已开发出来的分类算法进行辅助审计。分类挖掘的重点是特征选取、选择训练样本和分类器。 特征选择是模型进行计算的基础,指标变量选择的好坏直接影响到挖掘结果的质量。国内外已有很多关于这方面的文献可供参考,一般可选择下列指标: (1)盈利能力指标 包括总资产净利润率、资产报酬率、净资产收益率、营业收入净利润率、每股收益、营业毛利率、股东权益净利润率等。 (2)结构性指标 包括资产负债率、固定资产比率、营运资金对资产总额比率、应收账款占主营业务收入比重、营业利润比重、产权比率等。例如签订销售合同物权尚未转移时确认收入或者将库存商品确认为主营业务收入,同时增加应收账款,使主营业务收入虚增,形成白条利润,同时又通过应收账款虚增了资产,这样会造成应收账款占主营业务收入的比重发生异常。