云南省图书馆机构用户,欢迎您!
本文运用词源统计分析法,对壮侗语族语言做出数理分类以及亲缘关系程度的描述,并通过树枝长短来表示距离关系。显示壮侗语族语言的类簇和分级层次。同时计算出壮侗语族诸语言的时间深度,并分析其形成过程。以新的资料和方法,质疑传统的语言分类理论和方法,并试图提出新的东亚语言区域形成的理论解释。
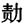 (1954)分中国境内的壮侗语族为3个语支(注:壮侗语族的民族的来源:民族学比较一致的观点,壮侗语族是古代百越民族的后裔,其谱系的历史演化过程:传说时代的“蛮”、“三苗”——商周时代的“瓯”、“越沤”——春秋战国汉时代的“百越”——晋唐时代的“俚”、“僚”民族集团——宋元时代的壮、侗、水、傣、毛南诸壮侗语族民族。百越是中国东南和南部地区古代民族的名称。新石器时代晚期是奠定民族形成的时期,南中国的人群已开始具有明显的区域特点。)。即壮傣语支、侗水语支、黎语支。罗、傅的分类近似李。 《中国语言地图集》(1988)(以下简称地图)则沿袭罗、傅的分类,分壮侗语族14种语言为3个语支: 壮傣语支:壮语,布依语,傣语,临高话。 侗水语支:侗语,水语,仫佬语,毛南语,佯璜语,莫语,拉珈语。 黎语支:黎语和村话。 此外仡佬语是否作为语支未定。。 梁敏、张均如(1996)的分类与《地图》相似,只是将仡佬语支作为独立语支单立。 本尼迪克特(Benedict,1990)有关壮侗语的分类跟别家不同处是:分别将仡佬、黎语、临高(Be)在三个不同的层次上独立,他运用的是树图的每个分叉点上的二分法,不同于李方桂等人的三分或四分法。本尼迪克特同时认为他的“澳台语系”跟“南亚语系”有一定的底层上的联系。 壮侗语专家W.J.Gedney(1993)将壮侗语族三分,即泰、侗水、黎和临高。其特点是将黎语、临高(Be)单立为一支。 1.2 分类的标准 历史语言学认为,语言的分类主要依据语言的相似性特征。语言的相似性特征可以有匹种解释:a.语言平行演变的结果,由于语言发展的普遍性特征导致不同语言的相似性特征。b.由于语言演变的偶然性造成语言之间的相似性特点。c.语言共同来源的保留。d.语言之间相互借用。 李方桂(1977)采用的是音韵学的标准,根据声母、韵母、声调在壮侗语中的不同反映模式来做壮侗的分类,语音的演变有严格的对应规律可循。他认为采取词汇的标准很危险,因为有大量的文化词不容易排除,而文化词是借用的结果。 但是,据最近罗永现(Luo,1997)对壮侗语族分类的研究,表明采用语音的分类标准与采用词汇的分类标准的结果是不同的。马提索夫(Matisoff,1985)认为语音的变化模式反映东南亚语言区域较晚期的面貌,例如声调的产生只在公元1500年代(中国的元、明时期),东南亚语言受到北方汉语的扩散,导致“北方化”的结果。他认同本尼迪克特依据基本词汇作为分类的标准的方法。 《地图》划分语支的依据主要是同源词的比率。各语支内部同源词约有45-75%,壮傣与侗水语的甲源词约为25-45%,壮傣语、侗水语与黎语的同源词约为22-27%。《地图》所依据的同源词的比率跟经典的语言分类的标准有一定的距离;传统的分类理论认为语言分类的标准有沟通度和基本词汇相似率两种。一些语言学家假定80%的基本词汇相似率,作为语言与方言的切分点。大于80%的基本词汇相似率的是方言,而小于80%的基本词汇相似率的则是不同的语言。但是,这也是个很任意的标准。 造成同源词比率统计差别的主要原因是用作统计的同源词的总数不同,例如梁敏、张均如(1996)用斯瓦迪什(Swadesh,1952、1955)提出200词作算术统计,就跟《地图》的算术统计结果不同。用作统计的词目越多,同源词比率就会越小。因为这存在词频和词的统计“权重”的问题。出现频率较多的词与出现频率较少的词放在一起统计,与完全统计出现频率高的词,其结果会不同。此外,统计的词目数量越大,就越难排除语言之间相互借用的成分。因为我们的目的是研究语言的发生学分类,并计算出语言的进化树分枝的时间深度,所以,应当尽量分清语言之间的同源和借用的关系。 1.3 各种分类的主要分歧
(1954)分中国境内的壮侗语族为3个语支(注:壮侗语族的民族的来源:民族学比较一致的观点,壮侗语族是古代百越民族的后裔,其谱系的历史演化过程:传说时代的“蛮”、“三苗”——商周时代的“瓯”、“越沤”——春秋战国汉时代的“百越”——晋唐时代的“俚”、“僚”民族集团——宋元时代的壮、侗、水、傣、毛南诸壮侗语族民族。百越是中国东南和南部地区古代民族的名称。新石器时代晚期是奠定民族形成的时期,南中国的人群已开始具有明显的区域特点。)。即壮傣语支、侗水语支、黎语支。罗、傅的分类近似李。 《中国语言地图集》(1988)(以下简称地图)则沿袭罗、傅的分类,分壮侗语族14种语言为3个语支: 壮傣语支:壮语,布依语,傣语,临高话。 侗水语支:侗语,水语,仫佬语,毛南语,佯璜语,莫语,拉珈语。 黎语支:黎语和村话。 此外仡佬语是否作为语支未定。。 梁敏、张均如(1996)的分类与《地图》相似,只是将仡佬语支作为独立语支单立。 本尼迪克特(Benedict,1990)有关壮侗语的分类跟别家不同处是:分别将仡佬、黎语、临高(Be)在三个不同的层次上独立,他运用的是树图的每个分叉点上的二分法,不同于李方桂等人的三分或四分法。本尼迪克特同时认为他的“澳台语系”跟“南亚语系”有一定的底层上的联系。 壮侗语专家W.J.Gedney(1993)将壮侗语族三分,即泰、侗水、黎和临高。其特点是将黎语、临高(Be)单立为一支。 1.2 分类的标准 历史语言学认为,语言的分类主要依据语言的相似性特征。语言的相似性特征可以有匹种解释:a.语言平行演变的结果,由于语言发展的普遍性特征导致不同语言的相似性特征。b.由于语言演变的偶然性造成语言之间的相似性特点。c.语言共同来源的保留。d.语言之间相互借用。 李方桂(1977)采用的是音韵学的标准,根据声母、韵母、声调在壮侗语中的不同反映模式来做壮侗的分类,语音的演变有严格的对应规律可循。他认为采取词汇的标准很危险,因为有大量的文化词不容易排除,而文化词是借用的结果。 但是,据最近罗永现(Luo,1997)对壮侗语族分类的研究,表明采用语音的分类标准与采用词汇的分类标准的结果是不同的。马提索夫(Matisoff,1985)认为语音的变化模式反映东南亚语言区域较晚期的面貌,例如声调的产生只在公元1500年代(中国的元、明时期),东南亚语言受到北方汉语的扩散,导致“北方化”的结果。他认同本尼迪克特依据基本词汇作为分类的标准的方法。 《地图》划分语支的依据主要是同源词的比率。各语支内部同源词约有45-75%,壮傣与侗水语的甲源词约为25-45%,壮傣语、侗水语与黎语的同源词约为22-27%。《地图》所依据的同源词的比率跟经典的语言分类的标准有一定的距离;传统的分类理论认为语言分类的标准有沟通度和基本词汇相似率两种。一些语言学家假定80%的基本词汇相似率,作为语言与方言的切分点。大于80%的基本词汇相似率的是方言,而小于80%的基本词汇相似率的则是不同的语言。但是,这也是个很任意的标准。 造成同源词比率统计差别的主要原因是用作统计的同源词的总数不同,例如梁敏、张均如(1996)用斯瓦迪什(Swadesh,1952、1955)提出200词作算术统计,就跟《地图》的算术统计结果不同。用作统计的词目越多,同源词比率就会越小。因为这存在词频和词的统计“权重”的问题。出现频率较多的词与出现频率较少的词放在一起统计,与完全统计出现频率高的词,其结果会不同。此外,统计的词目数量越大,就越难排除语言之间相互借用的成分。因为我们的目的是研究语言的发生学分类,并计算出语言的进化树分枝的时间深度,所以,应当尽量分清语言之间的同源和借用的关系。 1.3 各种分类的主要分歧