云南省图书馆机构用户,欢迎您!
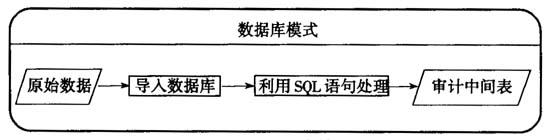 图一 数据库模式 数据库模式依托成熟的数据库管理系统与简洁的SQL语言,在审计实务中得到广泛使用,其在处理中小规模数据时非常有效,但在处理海量数据时在处理设备、处理效率上受到一定限制,很多原本有效的处理技术无法应用于海量数据。 (三)文本文件模式及特点 数据库模式效率开始下降或无法处理时,一般会选择更换更好的处理设备以提升数据处理效率,但这种方式需要大量的硬件成本,并且提升效果有限。文本文件模式是笔者在审计实践中探索出的一种基于文本文件操作的海量审计数据处理模式,即直接在文本文件上完成绝大部分的数据处理任务,然后将处理结果导入数据库后生成审计中间表。文本文件模式的结构如图二。
图一 数据库模式 数据库模式依托成熟的数据库管理系统与简洁的SQL语言,在审计实务中得到广泛使用,其在处理中小规模数据时非常有效,但在处理海量数据时在处理设备、处理效率上受到一定限制,很多原本有效的处理技术无法应用于海量数据。 (三)文本文件模式及特点 数据库模式效率开始下降或无法处理时,一般会选择更换更好的处理设备以提升数据处理效率,但这种方式需要大量的硬件成本,并且提升效果有限。文本文件模式是笔者在审计实践中探索出的一种基于文本文件操作的海量审计数据处理模式,即直接在文本文件上完成绝大部分的数据处理任务,然后将处理结果导入数据库后生成审计中间表。文本文件模式的结构如图二。 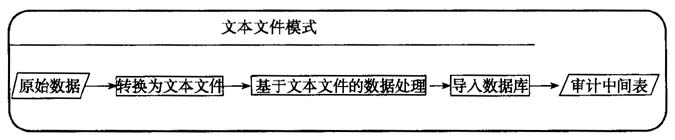 图二 文本文件模式 相对于数据库模式,文本文件模式能够突破设备配置、处理时效的限制,在普通设备上快速完成数据处理,具有设备要求低、处理速度快和处理方式灵活等特点。 二、文本文件模式的实现方法 虽然在《通用审计系统》等审计软件中具有部分文本文件处理功能,但还没有功能比较完整的处理工具。笔者在审计实务中通过编程实现了文本文件模式的部分功能,由于篇幅所限,在此只以流程图方式讨论审计数据处理中最常进行的数据质量检查、码表替换和数据抽取的实现。 (一)初步的数据质量检查与清洗 从被审计单位采集的数据在采集、转换等阶段可能会产生错误,因此需要在分析前对其完整性和正确性进行检查。文本文件模式直接以线性方式对文本文件进行解析,当一行文本无法正常解析时(即可能存在错误时),将其从整体数据分离,然后分析错误原因进行针对性修复,克服了数据库模式无法修复特殊字符造成的转换错误等缺点,其实现流程如图三。
图二 文本文件模式 相对于数据库模式,文本文件模式能够突破设备配置、处理时效的限制,在普通设备上快速完成数据处理,具有设备要求低、处理速度快和处理方式灵活等特点。 二、文本文件模式的实现方法 虽然在《通用审计系统》等审计软件中具有部分文本文件处理功能,但还没有功能比较完整的处理工具。笔者在审计实务中通过编程实现了文本文件模式的部分功能,由于篇幅所限,在此只以流程图方式讨论审计数据处理中最常进行的数据质量检查、码表替换和数据抽取的实现。 (一)初步的数据质量检查与清洗 从被审计单位采集的数据在采集、转换等阶段可能会产生错误,因此需要在分析前对其完整性和正确性进行检查。文本文件模式直接以线性方式对文本文件进行解析,当一行文本无法正常解析时(即可能存在错误时),将其从整体数据分离,然后分析错误原因进行针对性修复,克服了数据库模式无法修复特殊字符造成的转换错误等缺点,其实现流程如图三。 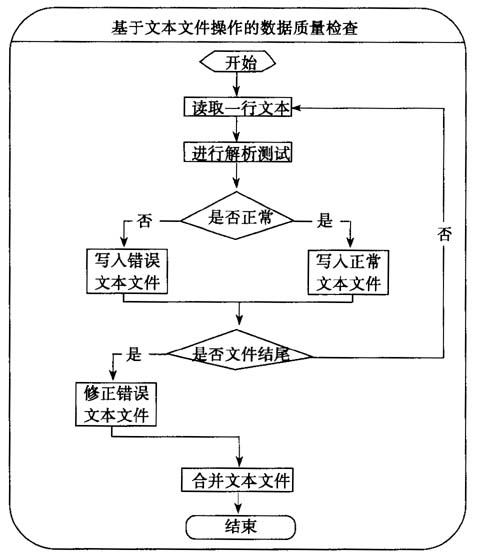 图三 文本文件模式下的数据质量检查 (二)代码字段的替换 审计数据中很多字段以代码方式表示,为方便审计人员理解,需要根据码表对其进行替换。由于码表一般都很小,文本文件模式先将码表读入内存以减少I/O访问,同时通过逐行解析文本对多个字段进行操作,克服了数据库模式一次只能处理一个字段的缺点,处理速度要远远高于数据库模式,其流程如图四。 (三)依据于内容的数据抽取 虽然海量审计数据的单表记录数很大,但在进行审计分析时一般只需要其中满足特定条件的一部分,因此需要将其从整体数据中抽取出来以提高分析效率。文本文件模式下可以直接逐行解析文本文件,判断该行内容是否满足抽取条件,能够达到快速抽取数据的目的,并且能完成数据库模式下无法完成的数据自动拆分,其流程如图五。 三、文本文件模式的应用效果
图三 文本文件模式下的数据质量检查 (二)代码字段的替换 审计数据中很多字段以代码方式表示,为方便审计人员理解,需要根据码表对其进行替换。由于码表一般都很小,文本文件模式先将码表读入内存以减少I/O访问,同时通过逐行解析文本对多个字段进行操作,克服了数据库模式一次只能处理一个字段的缺点,处理速度要远远高于数据库模式,其流程如图四。 (三)依据于内容的数据抽取 虽然海量审计数据的单表记录数很大,但在进行审计分析时一般只需要其中满足特定条件的一部分,因此需要将其从整体数据中抽取出来以提高分析效率。文本文件模式下可以直接逐行解析文本文件,判断该行内容是否满足抽取条件,能够达到快速抽取数据的目的,并且能完成数据库模式下无法完成的数据自动拆分,其流程如图五。 三、文本文件模式的应用效果 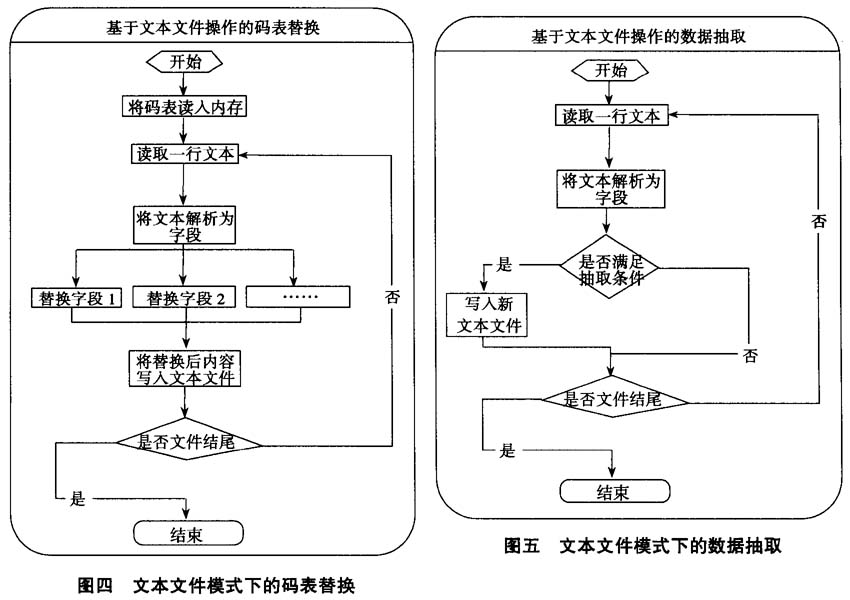 以某保险公司审计中的保单数据表为例,处理用计算机配置为1.6GCPU、512M内存、windows server2003操作系统。 被审计单位提供的数据为文本文件格式,2.94G,约629万条记录。该表中共有“险种”、“险类”、“保单种类”、“归属机构”和“业务来源”等8个代码字段,通过文本文件模式替换上述代码字段仅用26分钟时间,而在数据库模式下实现替换“险种”一个字段就需要32分钟(SQL语句为:update保单表set险种名称=(select险种名称from险种码表 where险种代码:保单表.险种代码))。
以某保险公司审计中的保单数据表为例,处理用计算机配置为1.6GCPU、512M内存、windows server2003操作系统。 被审计单位提供的数据为文本文件格式,2.94G,约629万条记录。该表中共有“险种”、“险类”、“保单种类”、“归属机构”和“业务来源”等8个代码字段,通过文本文件模式替换上述代码字段仅用26分钟时间,而在数据库模式下实现替换“险种”一个字段就需要32分钟(SQL语句为:update保单表set险种名称=(select险种名称from险种码表 where险种代码:保单表.险种代码))。