云南省图书馆机构用户,欢迎您!
本文利用KMV模型,对我国四家农业类上市公司6年的股票价格进行违约距离的实证计算和分析,确定了适合我国农业上市公司的预期违约率(Expected Default Frequency)计算公式。实证结果表明,KMV模型的灵敏度和预测能力较好,能为银行和投资者预测、揭示农业类上市公司信用风险。
 2.计算违约距离DD与期望违约率EDF。 违约距离作为一个度量信用风险的指标,指的是公司资产价值的期望值到违约点之间距离,以资产市场价值的标准差个数表示。计算公式如下:
2.计算违约距离DD与期望违约率EDF。 违约距离作为一个度量信用风险的指标,指的是公司资产价值的期望值到违约点之间距离,以资产市场价值的标准差个数表示。计算公式如下:  其中,式(3)和式(4)是假设资产价值服从正态分布推出,式(5)和式(6)是假设资产价值服从对数正态分布推出;
其中,式(3)和式(4)是假设资产价值服从正态分布推出,式(5)和式(6)是假设资产价值服从对数正态分布推出;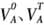 是期初和期末的资产价值,μ是资产的连续回报,其他符号同前。这里,目前国内大部分实证研究论文都是采用公式(3),石晓军2004采用过公式(5),公式(4)由本文提出,公式(4)和(6)的实证分析尚未见到。本文则在实证分析的基础上,对以上4个公式进行了分析和比较,选出适合我国国情的计算公式。 KMV公司计算预期违约频率采用的是将违约距离与公司的历史违约频率相匹配完成的。由于需要大量的历史数据,这一点在我国条件还不具备,所以本文暂且采用理论上的预期违约频率来代替。假设公司资产价值服从对数正态分布,那么理论上公司的期望违约率EDF为: P=N(-DD)=1-N(DD)(7) 式中,N(·)为标准正态分布函数。 二、样本数据准备 由于ST公司比一般正常的上市公司具有较高的信用风险(违约风险),为了便于说明问题和对比,本文选取了有代表意义的ST公司和正常的上市公司这两类样本进行研究。样本数据取自上海证券交易所农业类上市公司,随机选取两家被ST的公司,ST天香和ST秦丰,业绩相对较好的两家公司,伊利股份和赤天化。本文的实证计算做了如下假定:(1)假定公司股票价格服从对数正态分布;(2)利率使用一年期定期存款利率,我国的银行体制决定了银行存款的相对风险较低特点,可以视存款利率为无风险收益率;(3)股票波动率采取我国股票市场上的历史数据进行计算估计;(4)上市公司的股权市场价值由流通股市场价值和非流通股市场价值两部分组成,基于股权分置改革的陆续到位和大小非的成功解禁,本文视流通股和非流通股有同样的市场价值;(5)不考虑公司具体的债务结构,将公司债务等于短期债务(流动负债)加长期债务的一半。
是期初和期末的资产价值,μ是资产的连续回报,其他符号同前。这里,目前国内大部分实证研究论文都是采用公式(3),石晓军2004采用过公式(5),公式(4)由本文提出,公式(4)和(6)的实证分析尚未见到。本文则在实证分析的基础上,对以上4个公式进行了分析和比较,选出适合我国国情的计算公式。 KMV公司计算预期违约频率采用的是将违约距离与公司的历史违约频率相匹配完成的。由于需要大量的历史数据,这一点在我国条件还不具备,所以本文暂且采用理论上的预期违约频率来代替。假设公司资产价值服从对数正态分布,那么理论上公司的期望违约率EDF为: P=N(-DD)=1-N(DD)(7) 式中,N(·)为标准正态分布函数。 二、样本数据准备 由于ST公司比一般正常的上市公司具有较高的信用风险(违约风险),为了便于说明问题和对比,本文选取了有代表意义的ST公司和正常的上市公司这两类样本进行研究。样本数据取自上海证券交易所农业类上市公司,随机选取两家被ST的公司,ST天香和ST秦丰,业绩相对较好的两家公司,伊利股份和赤天化。本文的实证计算做了如下假定:(1)假定公司股票价格服从对数正态分布;(2)利率使用一年期定期存款利率,我国的银行体制决定了银行存款的相对风险较低特点,可以视存款利率为无风险收益率;(3)股票波动率采取我国股票市场上的历史数据进行计算估计;(4)上市公司的股权市场价值由流通股市场价值和非流通股市场价值两部分组成,基于股权分置改革的陆续到位和大小非的成功解禁,本文视流通股和非流通股有同样的市场价值;(5)不考虑公司具体的债务结构,将公司债务等于短期债务(流动负债)加长期债务的一半。