一 现在世界范围的自然语言处理研究工作,大致都停留在句处理阶段。其进展不像希望的那样快。句处理的核心问题是怎么让计算机处理、理解自然语言中一个句子的意思,又怎么让计算机自动生成一个符合自然语言规则的、让人能理解的句子。在这个问题的解决上,现在可以说是八仙过海、各显神通。从大的方面说,大致有两种策略,一种是基于规则的处理策略,要求研究者拥有两方面的语言知识:一是范畴 (category)知识,二是规则(rule)知识。范畴知识有句法的,有语义的;句法的如主语、谓语、宾语、定语以及名词、动词、形容词等,语义的如施事、受事、工具以及数量、领属、自主、位移等。范畴用来刻画语言对象的一个或一组特征。规则用来表述范畴间的关系。一个范畴可能刻画为几个特征,一个特征也可能用来刻画多个范畴。所有规则都是建立在已知的或者更确切点说是假设的范畴的基础上。从逻辑上来说,所有规则都可以表示为P→Q这样的蕴涵式。比如,可以有这样的规则,如果某个词W是名词(P),那么W能作主语 (Q)。这条规则在‘“名词’”跟‘“主语’”两个范畴间建立起了一种联系,尽管这条规则所描述的联系是粗糙的,甚至不那么正确,但是,以这样的方式建立范畴之间的联系,是分析语言的结构时必不可少的。而语言学家所要做的,正是去寻找正确的和好的联系。范畴知识一般用词库(机器可读词典MRD)来负载,规则知识则由所谓规则库(规则的集合)来承担。计算机建立了词库和规则库,就可以利用这些词库和规则库,按研究者的需要进行运算、分析,然后研究者根据计算机的分析结果(着重看计算机的分析结果是否跟预期的要求或目标相符),来调整原有的范畴体系、具体语言成分的属性取值以及相关的规则,即改进词库和规则库的内容。基于统计的“句处理”研究,主要借助于计算机对大规模语料库真实文本的统计分析,由计算机来抽象出语言知识。因此,基于统计的“句处理”,其重要依靠就是存放实际的语言交际中真实出现的语言材料的语料库(corpus)。语料库可以分“生语料库”和“熟语料库”。所谓生语料库,是指未加工的、未带有任何语言学信息标注的语料库;所谓熟语料库是指经过词的切分、词性标注等一定加工的、带有语言学信息标注的语料库。[7]、[8]可见,建设一个语料库,除了通过某种手段录入大量语料外,重要的是要对所录入的语料进行如下的标注加工: 词的切分(Segmentation,或者说“分词”) 词性标记(Part-of-speech tagging) 句法层次和范畴标记(Grammatical parsing) 词义标记(Word sense tagging) 篇章指代标记(Anaphoric annotation) 韵律标记(Prosodic annotation) 以上是从大的方面说的。从小的方面说还各有招术。但不管用什么策略,用什么招术,都有赖于或者说都离不开有关自然语言的各种资源,特别需要语法、语义等多方面分析研究成果的支撑。具体到中文信息处理,那就是离不开有关汉语的资源或者说知识。面向中文信息处理的汉语资源建设,已成为中文信息处理,乃至我国的信息科技发展的关键性工程。在汉语资源的建设中,揭示、描述句法语义的互动、接口(in terface)问题是其中的一个重要组成部分[2]。 二 朱德熙先生[9]生前一直强调语法研究中形式和意义的结合。这是从汉语本体研究的角度来说的,是从汉语本体研究中悟出的道理。从中文信息处理的角度说,亟须从交际过程中编码、解码的角度来考虑问题。从交际过程中编码、解码的过程来说,就是要解决好句法、语义的接口问题。 怎么解决好句法语义的接口问题?现在大家还是在探索之中。句法语义的接口问题,我想,是否可以有不同的研究、探索的思路。 一种是从考虑句子意思的组成的角度来研究探索,研究探索一个句子的意思是由哪些意义编织成的,这些意思是怎样编制成一个句子的意思的。这个思路可以看作是由外往里的思路。另一种是考虑人到底是怎么把自己对于客观世界的认知所得通过言辞表达出来的。这个思路可以看作是由里往外的思路。 就前一种思路说,一个句子的意思是由哪些意义编织成的,是值得考虑、研究的。我先前曾认为,句子的意思是由这样一些意义组成的[3]:
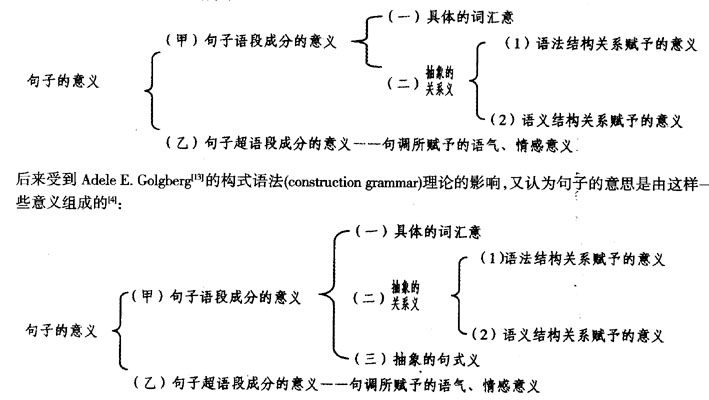
现在先且不说一个句子的意思是不是由这些意义组成的,即使承认是由这些意义组成的,也还存在一个问题:这些不同的意义是怎样编制成句子的意思的? 就后一种思路来说,王黎[6]提出了这样一种看法:从客观世界到最后用言辞把人的感知所得表达出来,这中间一共可以分为五层(以存在事件为例,见下页图表): 以上当然也还只是一种假设。但这一假设为我们深入探索句法与语义的接口问题提供了一种思考的基础;而且,从实际的话语交际中,我们确实也可以体会到: