云南省图书馆机构用户,欢迎您!
数理统计法在诗文用韵研究上的应用。韵段分组方法的不同影响样本的分布形态,合适的分组办法可以使样本呈正态分布。利用计算机分析宋词山咸深臻梗曾诸阳声韵摄的数据,山咸二摄阳声韵按介音有无分成洪细两组,分别合用较多,应当合并为一部;深摄与臻梗曾摄、梗曾摄与臻摄的合用都属于韵尾相近而正常通押的范围内,应当各自独立。
 公式①计算两个韵部j、k之间关系的辙离合指数,公式②③计算两个韵a、b之间关系的韵离合指数。公式①除号以前的数值代表j、k韵部实际相押的比率,后面括号内的数值代表理论上随机相押的比率。这个随机相押的比率是通过排列组合原理得出来的,有个形象的比方,就是从总数为Z的球袋中摸球,第一个摸出是标签是j的球的概率为Zj/Z,第2个摸出标签是k的球的概率则是Zk/Z-1。这样两个球恰好前j后k的概率就是两者的乘积,同理再加上两个球前k后j的概率,就构成了i、k两辙随机相押的总概率。公式②③朱晓农先生未多加解释,但似乎和公式①略有不同,被除数仅是a、b两韵的总字次和总韵次,而把同一个韵段中a、b韵和其他韵组成的韵次置之不理,无形中可能放大了概率,不符合排列组合的精神。两个公式既然是从同一个原理推导而来,应该算法相同较为恰当。因此我们将韵离合指数的公式修改为:
公式①计算两个韵部j、k之间关系的辙离合指数,公式②③计算两个韵a、b之间关系的韵离合指数。公式①除号以前的数值代表j、k韵部实际相押的比率,后面括号内的数值代表理论上随机相押的比率。这个随机相押的比率是通过排列组合原理得出来的,有个形象的比方,就是从总数为Z的球袋中摸球,第一个摸出是标签是j的球的概率为Zj/Z,第2个摸出标签是k的球的概率则是Zk/Z-1。这样两个球恰好前j后k的概率就是两者的乘积,同理再加上两个球前k后j的概率,就构成了i、k两辙随机相押的总概率。公式②③朱晓农先生未多加解释,但似乎和公式①略有不同,被除数仅是a、b两韵的总字次和总韵次,而把同一个韵段中a、b韵和其他韵组成的韵次置之不理,无形中可能放大了概率,不符合排列组合的精神。两个公式既然是从同一个原理推导而来,应该算法相同较为恰当。因此我们将韵离合指数的公式修改为: 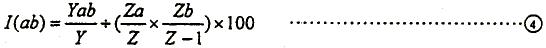 这样,公式④和公式①的原理保持一致(因为韵组是组合而来的,这里我们也用组合,不用排列,所以不乘于2)。将所有含有a韵韵字或b韵韵字的韵段作为样本,Y指样本的总韵组,Z指样本的总字次。当I(ab)<50时,认为ab两韵应分开,当I(ab)>=90时,认为ab两韵应合并,当50<=I(ab)<90时,需要进行假设检验(注:I(ab)的两端是50和90,为什么是这两个数字,朱晓农先生没有详细讨论,看来是一个经验值。)。 1.3 使用假设检验的前提是首先要保证样本有足够的数量,宋词用韵样本数(韵段数)大多在几百以上,多的甚至达到上千,符合这一要求。有些学者在某个词人总的词作才几十首、全部韵段不过百多个的情况下使用数理统计法,其结论不能不让人感到怀疑。虽然t检验是适用于小样本分析的方法,但是对样本的数量仍有一定的要求,当原始数据量较小时,结果的可靠性就很差。麦韵先生特意强调,对于字次小于10的韵,即使它与别韵的离合指数在50到90之间,也不再进行t假设检验;两韵互押不到5次的,也不做检验[4]p115,这种做法是比较科学的。 其次,样本的分组影响数据的分布。诗文用韵研究中的样本是韵段中通押韵组与该韵段全部韵组的比率。比方说我们考察宋词韵里面侵韵跟真韵的关系,首先把含有侵韵或真韵的韵段搜集一起作为样本,一共有1930个。可以分为两类:一类是侵真合用的韵段,有211个,如苏轼《江城子·腻红匀脸》(一329):唇谆新真春谆颦真人真阴侵深侵心侵今侵,这个韵段中侵真合用韵组12个,全部韵组36个,那么比率就是0.3333;另一类是非侵真合用韵段,有1719个,如柳永《甘草子·秋尽》(一15):尽真粉信真紧真嫩顿恨,晏殊《浣溪沙·三月和风》(一88):林侵金侵阴侵心侵深侵。这类韵段侵真合用韵组为零,因此比率都是零。如果我们直接以每个韵段的比率作为样本,那么大部分样本都是零,这样的样本呈偏态分布。偏态分布可以利用box-cox公式模型化为正态分布,但是无疑影响统计的结果。
这样,公式④和公式①的原理保持一致(因为韵组是组合而来的,这里我们也用组合,不用排列,所以不乘于2)。将所有含有a韵韵字或b韵韵字的韵段作为样本,Y指样本的总韵组,Z指样本的总字次。当I(ab)<50时,认为ab两韵应分开,当I(ab)>=90时,认为ab两韵应合并,当50<=I(ab)<90时,需要进行假设检验(注:I(ab)的两端是50和90,为什么是这两个数字,朱晓农先生没有详细讨论,看来是一个经验值。)。 1.3 使用假设检验的前提是首先要保证样本有足够的数量,宋词用韵样本数(韵段数)大多在几百以上,多的甚至达到上千,符合这一要求。有些学者在某个词人总的词作才几十首、全部韵段不过百多个的情况下使用数理统计法,其结论不能不让人感到怀疑。虽然t检验是适用于小样本分析的方法,但是对样本的数量仍有一定的要求,当原始数据量较小时,结果的可靠性就很差。麦韵先生特意强调,对于字次小于10的韵,即使它与别韵的离合指数在50到90之间,也不再进行t假设检验;两韵互押不到5次的,也不做检验[4]p115,这种做法是比较科学的。 其次,样本的分组影响数据的分布。诗文用韵研究中的样本是韵段中通押韵组与该韵段全部韵组的比率。比方说我们考察宋词韵里面侵韵跟真韵的关系,首先把含有侵韵或真韵的韵段搜集一起作为样本,一共有1930个。可以分为两类:一类是侵真合用的韵段,有211个,如苏轼《江城子·腻红匀脸》(一329):唇谆新真春谆颦真人真阴侵深侵心侵今侵,这个韵段中侵真合用韵组12个,全部韵组36个,那么比率就是0.3333;另一类是非侵真合用韵段,有1719个,如柳永《甘草子·秋尽》(一15):尽真粉信真紧真嫩顿恨,晏殊《浣溪沙·三月和风》(一88):林侵金侵阴侵心侵深侵。这类韵段侵真合用韵组为零,因此比率都是零。如果我们直接以每个韵段的比率作为样本,那么大部分样本都是零,这样的样本呈偏态分布。偏态分布可以利用box-cox公式模型化为正态分布,但是无疑影响统计的结果。