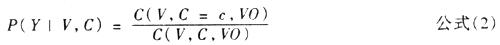[中图分类号]H08 [文献标识码]A [文章编号]1003-5397(2005)01-0137-07 一 引言 (一)研究目标的确定 本文的研究目标是:对一个经过分词和词性标注处理的汉语句子,通过自动分析确定 句子中动词的宾语,即识别汉语文本中的动宾搭配。本文所指的动宾搭配,是指只带一 个体词性宾语的动词和在句子中位于其后的体词之间构成的述宾关系。例如: 现在/t 大陆/nps 确立/vgn 了/utl [建立]/vgn 社会主义/ng 市场/ng 经济/ ng 体制/ng 的/usde 改革/vgp 目标/ng 。/。 当前动词为“建立”,我们的目标是找出它的宾语“体制”。因为我们的主要目标是 从文本中抽取词语的搭配知识,而不是进行句法分析,所以,当动词的宾语是一个复杂 的名词性短语时,我们只找出其中心词,而不是整个短语。 就处理范围而言,我们并不是面向全部动宾搭配。从动词来看,我们只考虑了体宾动 词。这样的选择是因为:体宾动词在动词中占绝大多数。从词语搭配的角度看,动词和 名词之间的搭配是最重要的。从宾语来看,我们所说的宾语仅限于真宾语。 (二)研究价值 1.为建立词语搭配知识库提供有效工具 词语搭配是十分重要的语言知识。由于这样的搭配在使用上习惯性很强,规律性相对 较弱,用规则难以概括。倘若建立词语搭配知识库,收录从真实文本中提取的词语搭配 ,就可以为自然语言处理和语言教学提供重要的知识来源。 2.为关于动词的句法研究提供工具 动词和动词性结构是语言研究中的核心问题之一。而研究动词,可以就动词本身研究 动词,但更重要的是研究句子里边的动词和有关成分,主要是名词成分的关系。建立动 名搭配知识库,可以为研究动词和名词的组合关系提供定量分析的数据。 3.为句法分析提供有用的信息 搭配提取是句法分析的关键环节,动宾搭配是句内的核心成分,是整个句子的轮廓。 假如能准确识别出动宾结构,我们就有可能为实现完全的句法分析奠定一定的研究基础 。 (三)相关研究综述 对于什么是搭配,过去语言学家Choueka(1983),Church and Hanks(1989),Benson等 由于理论背景和应用目的的不同,存在着不同的理解。 汉语的搭配提取,经历了从笼统的研究所有的搭配到分门别类地研究各种类型的搭配 的过程。 孙茂松等《汉语搭配定量分析初探》提出了包括强度、离散度及尖峰三项统计指标在 内的搭配定量评估体系,并据之构造了相应的搭配判断算法。实验结果显示,就“能力 ”一词而言,算法自动发现搭配的准确率约为33.94%。 孙宏林《从标准语料库中归纳语法规则:“V + N”序列实验分析》采用了规则和统计 相结合的方法——从大规模标注语料库中归纳语法规则,来识别动宾搭配。 陈小荷《动宾组合的自动获取与标注》采用统计方法在语料中自动获取动宾组合实例 ,并将未经校对的搭配数据用于动宾结构的自动标注,以检测自动获取的数据价值。正 确率和召回率分别达到74.7%和76%。 二 统计模型 我们全面剖析了搭配的语音、语法和语义特征,并分析了一定数量的统计数据,在此 基础上构造了动宾搭配自动获取的统计计算模型,力图采用多项统计量,全面考虑搭配 的各项性质。我们选用的统计量有:VN结构概率、语义搭配概率、音节搭配概率和跨度 搭配概率。分别考查了搭配的重复出现性、语义约束、音节限制和结构性。 (一)VN结构概率 搭配的一个重要性质是构成搭配的词语在文本中经常共同出现(Benson 1985),但并不 是经常共现的词语就一定构成搭配关系。我们采用条件概率(Conditional Probability )来描述一个动词和一个名词共现时它们构成动宾关系的概率:P(Y|V,N)表示当(V,N )在一定范围内共现时(V,N)构成动宾关系的概率。我们可以根据极大似然估计(MLE)从 一个标注了动宾关系的语料库中估计这一概率值:
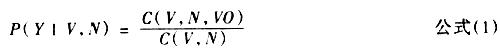
其中,C(V,N,VO)表示(V,N)在语料中构成动宾关系的频次,C(V,N)表示(V,N)在 一定范围(本文中指一个小句,即由标点逗号、分号、冒号、句号、问号、感叹号将文 本分割成的句法单位)内共现的频次。 公式(1)虽然能很好地描述一个动词和一个名词构成搭配的概率,但由于它依赖两个词 形的共现,所以在概率估计上会遇到严重的数据稀疏问题。我们解决这一问题的方法是 从基于具体词形的概率模型回退(back-off)到基于语义类的概率模型。