1.引言:汉语词类模糊划分的基本步骤 笔者在《词类范畴的家族相似性》(注:袁毓林:《词类范畴的家族相似性》,《中国 社会科学》1995年第1期。)一文中,曾经尝试用原型理论来考察汉语词类的范畴性质, 指出汉语词类是一种原型范畴,是根据词与词之间在分布上的家族相似性而聚集成类的 。但是,当时还不能从操作上提出有效的方法。此后,我们逐步认识到:既然汉语词类 并不是边界明确的普通集合,而是从内涵到外延都不甚清晰的模糊集合;对于为数众多 的词来说,它们跟某些词类的隶属关系并不是简单的是(即隶属度为1)或非(即隶属度为 0)这种两极对立,而只是在一定程度上属于某一种或几种词类。那么,我们应该运用模 糊数学中的模糊集合(fuzzy set)和模糊聚类(fuzzy clustering)的有关观念和方法来 处理汉语词类问题。于是,形成了这样的研究思路:采用动态聚类的方法,以各词类的 典型成员作为初始的聚类中心。具体的工作步骤是:首先,根据每类词的典型成员的语 法表现,来选定一组分布特征;并按照这些不同的分布特征对于相关词类的重要性,根 据经验给其中的每个特征设定权值(weight);其中有正分(即加分),也有负分(即扣分) 。然后,计算总分,典型成员应该得100分或接近100分,非典型成员则小于100分、但 一般大于50分。最后,折合成介于区间[0,1]中的不同的值来描写词类归属模糊的词对 于有关词类的隶属度(degree of membership),从而从量上确定这些词的词类归属。比 如,某个词相对于某种词类的隶属度越趋近1,那么就越趋近该词类的典型成员。这时 ,根据实际的测试,借鉴利用模糊关系进行聚类的方法中的λ值设定法,通过设定不同 的λ值,来确定不同的词从属于某个词类的典型性等级。比如,隶属度0.8以上为典型成员,0.6以上为一般成员,0.6以下为非典型成员。当一个词从属于不同的词类的最高得分相同或相近时,就说明该词兼属于这些词类(即一词多类)。 为了达到上述目标,我们先后调查和分析了近万个词类归属比较明确的常用词的分布 情况,以设定不同词类的有关分布特征的权值。接着,又调查和分析了上千个词类归属 不明的常用词的分布情况,以此作为对先前设定的分布权值的校验;然后用校验过的权 值来计算它们相对于有关词类的得分情况,确定这些词对于有关词类的隶属度;并对这 种校验过的权值的合理性进行评估,不断地加以修正,尽可能调整到令人满意的水平。 现在,我们先有选择地公布这套用以对汉语词类进行模糊划分的分布特征及其权值设 定,希望它们能够成为对现代汉语的词进行隶属度计算和模糊聚类的量表(scale)或标 尺性的东西(yardstick),借此可以对现代汉语的词类进行模糊划分。 2.权值设定和隶属度计算的约定 为了统一规范和便于计算,我们制定如下关于分布特征的权值设定和有关词对于有关 词类的隶属度的计算办法的约定: (1)任何一个词,它对于某个词类的隶属度,总是在闭区间[0—1]之间。 (2)假定一个词完全满足某个词类的各种主要的分布特征时得100分,即它完全属于这 一词类;那么,它属于这一词类的隶属度为1。 (3)假定一个词完全不满足某个词类的各种主要的分布特征时得0分,即它根本不属于 这个词类;那么,它属于这一词类的隶属度为0。 (4)每个分布特征的权值根据经验来设定,符合该特征的得正分,不符合一般特征的得 零分,不符合关键特征的得负分。 (5)根据一个词的总的得分(积分)来计算(折合)其相对于某个词类的隶属度,并且取其 中最大的隶属度作为判定其词类归属的根据。如果最大的隶属度是相等的两个、或接近 相等的两个或多个,那么这个词可能兼属于两种或多种词类。 (6)当某个词对于某个词类的积分小于0时,按照0来计算。 3.各别词类的分布特征和权值设定 限于篇幅,下面只列出判定名词、时间词、方位词、处所词、动词、形容词、状态词 、区别词、副词等9种词类的有关的分布特征及其权值设定。 3.1 名词的分布特征和权值设定 (1)一般可以受数量词的修饰。(注:为了行文简便和流畅,本文对于诸如“名词可以 受数量词修饰,不受[单音]副词修饰;时间词可以作‘在、到、从、等到’的宾语;处 所词可以作‘在、到、从、往’的宾语;形容词可以受‘很’修饰;……”等自Chao Yuen Ren(1968)、朱德熙(1982)以来已经深入人心的分布特征,基本上不加出处。这里 先一并作出声明,以示郑重。)例如:
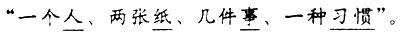
这种分布特征的形式表示是:SL__;其 中,SL代表数量词。 如果某词满足这种分布(即能进入这一分布框架,记作:√),那么它在名词性方面得1 0分(记作:WV = 10,WV是weight value的缩写);也就是说,光凭该词的这种分布特征 (distribution feature,缩写为DF),该词对于名词这个词类的隶属度为0.1(记作:DM = 0.1,DM是degree of membership的缩写)。相反,如果某词不满足这种分布(即不能进入这一分布框架,记作:×),那么该词的这种分布特征使得它在名词性方面得0分;也就是说,光凭该词的这种分布特征,该词对于名词这个词类的隶属度为0。