云南省图书馆机构用户,欢迎您!
对目前音韵学中所用的统计方法进行了全面的比较,分析了统计法在音韵研究中的必要性和可行性,强调了统计法的科学性,并从统计学原理、方法的引入、运用中的注意事项和统计法在音韵学运用中的优势和不足等方面对三种统计方法进行了详细的阐述。
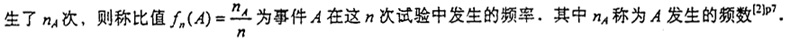 简之,频率便是部分在总体中所占的比值。在音韵研究中,常用百分数来表示。这种方法在当代音韵研究中运用最普遍,例如罗常培先生的《切韵鱼虞之音值及其所据方音考》、邵荣芬先生的《切韵研究》等。 概率统计法,就是先假设某语音材料在音理上是何种情况,再利用概率论的一些基本原理和公式,计算出该语音材料各个类别在理论上的数值,然后再用实际数值与之比较,以确定前面的假设是否成立,得出正确的结论,而音韵学中的概率统计法实际就是几遇数统计在音韵学中的具体运用。 数理统计法是以概率论为基础,有效地整理和分析带有随机性质的数据,对所观察的问题做出推断和预测,然后再用假设检验来最终判断语音的发展趋势和推测当时的实际情况。 依据统计学的原理来分析,一个完整的统计过程可分为四个阶段:统计设计、统计调查、统计整理、统计分析。音韵学中的“算术统计法”只是数据分类和简单运算,只进行到统计整理阶段,为统计分析做准备,应属于未完成的统计工作。而“概率统计法”和“数理统计法”实际上都是以概率论为理论基础,之所以分为两种,只是依据其是否利用了假设检验,这由韵文材料的性质决定。 三 从方法的引入来分析 这三种方法引入音韵学研究中,目的都是为了避免随机误差。为了在研究反切材料时避免随机误差,引入了数据罗列法和几遇数统计法。为了在研究韵文材料时避免随机误差,引入了数理统计法。而比例统计法被认为是可应用于任何材料的方法。 白涤洲先生认为,古人做反切会有两个毛病:一是“同类的字太少,随便假借相近的别类字作切”,再就是“用字时偶然忽略,误用近似而非同类的字作切”,“我们若不把有这种毛病的字视为例外,严格的依据他考订,态度虽是十分谨严,而实际上反失之呆板[2]。陆志韦先生认为“系联之法,病在唐五代之治韵学者用字如或偶尔疏忽,则切上字之本不系联者或因而系联焉。其本当系联者或因而不系联焉。此则方法之弊。”另外,“陈澧之错失乃在据又切而合并声类”,因为“《广韵》又切之性质尚未有详细考核之者。”[3]白涤洲先生和陆志韦先生所说的毛病和弊端,用统计学的术语来说,就是古人在造反切时存在着随机误差,这有可能是作者偶误,也可能是后人传抄时的笔误,还有可能是后人的妄改。当然,随机误差还包括其它一些情况。这种误差若在研究中不能避免,所得结论难免失当,例如陈澧用反切系联法研究《广韵》的声类,尽管其基本条例、分析条例、补充条例使这种方法有一定的科学性,但实现这种科学性的前提有两点:一是古人的反切无误;二是要将条例贯彻到底,运用一致,否则,用基本条例不能系联的,有的用补充条例归并为一类,有的又不用补充条例把它们分为两类,从而又产生新的误差。例如,唇音“帮”与“非”、“滂”与“敷”、“併”与“奉”分为两类,是因为陈澧没有用补充条例,而“明”与“微”并为一类是因为他用了补充条例。这就说明,反切系联法本身不但无法消除随机误差,反而可能在实际运用中产生新的失误。
简之,频率便是部分在总体中所占的比值。在音韵研究中,常用百分数来表示。这种方法在当代音韵研究中运用最普遍,例如罗常培先生的《切韵鱼虞之音值及其所据方音考》、邵荣芬先生的《切韵研究》等。 概率统计法,就是先假设某语音材料在音理上是何种情况,再利用概率论的一些基本原理和公式,计算出该语音材料各个类别在理论上的数值,然后再用实际数值与之比较,以确定前面的假设是否成立,得出正确的结论,而音韵学中的概率统计法实际就是几遇数统计在音韵学中的具体运用。 数理统计法是以概率论为基础,有效地整理和分析带有随机性质的数据,对所观察的问题做出推断和预测,然后再用假设检验来最终判断语音的发展趋势和推测当时的实际情况。 依据统计学的原理来分析,一个完整的统计过程可分为四个阶段:统计设计、统计调查、统计整理、统计分析。音韵学中的“算术统计法”只是数据分类和简单运算,只进行到统计整理阶段,为统计分析做准备,应属于未完成的统计工作。而“概率统计法”和“数理统计法”实际上都是以概率论为理论基础,之所以分为两种,只是依据其是否利用了假设检验,这由韵文材料的性质决定。 三 从方法的引入来分析 这三种方法引入音韵学研究中,目的都是为了避免随机误差。为了在研究反切材料时避免随机误差,引入了数据罗列法和几遇数统计法。为了在研究韵文材料时避免随机误差,引入了数理统计法。而比例统计法被认为是可应用于任何材料的方法。 白涤洲先生认为,古人做反切会有两个毛病:一是“同类的字太少,随便假借相近的别类字作切”,再就是“用字时偶然忽略,误用近似而非同类的字作切”,“我们若不把有这种毛病的字视为例外,严格的依据他考订,态度虽是十分谨严,而实际上反失之呆板[2]。陆志韦先生认为“系联之法,病在唐五代之治韵学者用字如或偶尔疏忽,则切上字之本不系联者或因而系联焉。其本当系联者或因而不系联焉。此则方法之弊。”另外,“陈澧之错失乃在据又切而合并声类”,因为“《广韵》又切之性质尚未有详细考核之者。”[3]白涤洲先生和陆志韦先生所说的毛病和弊端,用统计学的术语来说,就是古人在造反切时存在着随机误差,这有可能是作者偶误,也可能是后人传抄时的笔误,还有可能是后人的妄改。当然,随机误差还包括其它一些情况。这种误差若在研究中不能避免,所得结论难免失当,例如陈澧用反切系联法研究《广韵》的声类,尽管其基本条例、分析条例、补充条例使这种方法有一定的科学性,但实现这种科学性的前提有两点:一是古人的反切无误;二是要将条例贯彻到底,运用一致,否则,用基本条例不能系联的,有的用补充条例归并为一类,有的又不用补充条例把它们分为两类,从而又产生新的误差。例如,唇音“帮”与“非”、“滂”与“敷”、“併”与“奉”分为两类,是因为陈澧没有用补充条例,而“明”与“微”并为一类是因为他用了补充条例。这就说明,反切系联法本身不但无法消除随机误差,反而可能在实际运用中产生新的失误。