云南省图书馆机构用户,欢迎您!
本文用计算语音对应规律性程度的方法测度语言间的远近关系,讨论了语音对应的计算方法。并将侗台语族若干种语言语音对应规律性程度值与已有的关于侗台语族语言间远近关系的认识相比较。
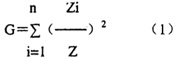 式(1)中n为一语言中某音类在另一语言中对应类型数。 我们的目标是计算出整个语音系统之间的总的对应规律性程度,而不只是某个音类的对应规律性程度,所以我们还要考虑如何能将语音系统中各音类在另一语音系统中的对应规律性程度综合起来。这里边有个问题,就是一种语言中音类有多个,而各音类在语言中包含的词(词素)个数并不相同,有些包含多些,有些包含少些。例如在商务1962年12月版的《简明英汉词典》中,以z打头的词只有47个,而以s打头的词则不下3000个。由于各音类包含的词(词素)个数不同,对系统总对应规律性程度的影响也就有差异。因此我们需要用各音类对应程度值的加权平均值来作为衡量系统对应规律性程度的指标。而各音类在系统中的权重,则可以以该音类包含词(词素)个数与系统总词(词素)个数的比值来决定。如果一个音类在一语言中包含词(词素)个数1000个,系统总词(词素)个数30000个,其权重就是1000/30000。设XZ为系统总词(词素)个数,则各音类对应规律性程度的加权值就是:
式(1)中n为一语言中某音类在另一语言中对应类型数。 我们的目标是计算出整个语音系统之间的总的对应规律性程度,而不只是某个音类的对应规律性程度,所以我们还要考虑如何能将语音系统中各音类在另一语音系统中的对应规律性程度综合起来。这里边有个问题,就是一种语言中音类有多个,而各音类在语言中包含的词(词素)个数并不相同,有些包含多些,有些包含少些。例如在商务1962年12月版的《简明英汉词典》中,以z打头的词只有47个,而以s打头的词则不下3000个。由于各音类包含的词(词素)个数不同,对系统总对应规律性程度的影响也就有差异。因此我们需要用各音类对应程度值的加权平均值来作为衡量系统对应规律性程度的指标。而各音类在系统中的权重,则可以以该音类包含词(词素)个数与系统总词(词素)个数的比值来决定。如果一个音类在一语言中包含词(词素)个数1000个,系统总词(词素)个数30000个,其权重就是1000/30000。设XZ为系统总词(词素)个数,则各音类对应规律性程度的加权值就是: 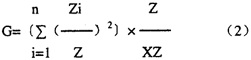 语音系统总对应规律性程度值就是各别音类对应规律性程度的加权值之和。设GZ为系统总对应程度值,式子表示就是:
语音系统总对应规律性程度值就是各别音类对应规律性程度的加权值之和。设GZ为系统总对应程度值,式子表示就是: 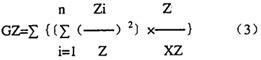 此外,语言间语音的对应是双向的,甲语言对乙语言形成的对应情况和乙语言对甲语言形成的对应情况是不同的。比如甲语言辅音[p]在乙语言中有[p][ph][b][m]等4种对应类型,而乙语言辅音[p][ph][b][m]在甲语言中却都只有[p]一种对应类型,就乙语言来说,4个辅音与甲语言都是单一的对应,而就甲语言来说,辅音[p]与乙语言却是一种复杂的对应。按照上面的方法计算,乙语言[p][ph][b][m]对甲语言的对应规律性程度都将是100%,它们的加权平均值也将是100%,而甲语言[p]对乙语言的对应规律性程度值必定在100%以下。所以以甲语言为主以乙语言为客,还是以乙语言为主甲语言为客进行计算,其结果会有差异。因此我们有必要先计算出两语言各为主时的单向对应规律性程度值,然后取两者的平均数,来作为其双向的系统对应规律性程度值。
此外,语言间语音的对应是双向的,甲语言对乙语言形成的对应情况和乙语言对甲语言形成的对应情况是不同的。比如甲语言辅音[p]在乙语言中有[p][ph][b][m]等4种对应类型,而乙语言辅音[p][ph][b][m]在甲语言中却都只有[p]一种对应类型,就乙语言来说,4个辅音与甲语言都是单一的对应,而就甲语言来说,辅音[p]与乙语言却是一种复杂的对应。按照上面的方法计算,乙语言[p][ph][b][m]对甲语言的对应规律性程度都将是100%,它们的加权平均值也将是100%,而甲语言[p]对乙语言的对应规律性程度值必定在100%以下。所以以甲语言为主以乙语言为客,还是以乙语言为主甲语言为客进行计算,其结果会有差异。因此我们有必要先计算出两语言各为主时的单向对应规律性程度值,然后取两者的平均数,来作为其双向的系统对应规律性程度值。