中图分类号 H085 文献标识码 A 文章编号 1671-9484(2002)01-0047-15 1 引言 机器翻译(Machine Translation)是指利用计算机程序把一种语言的文本(可称为源语言文本)翻译成另外一种语言的文本(可称为目标语言文本)。很久以来,人们就梦想着有朝一日,能造出一种设备,清除人类交流过程中的“语言障碍”,使得使用不同语言的人能自由地相互交流。(注:可以访问著名的《连线》(WIRED)杂志网站http://www.wired.com/wired/archive/8.05/timeline.html。这篇文章把机器翻译的理想上溯到1629法国数学家兼哲学家笛卡儿(René Descartes)时代。)在当代信息社会,语言障碍问题更加突出。大量的政府文件、商业以及科技资料都需要在短时期内得到翻译,互联网的问世更是扩大了翻译需求。可以说,人们现在比以往任何时候都迫切希望拥有自动翻译技术。然而,过去50多年机器翻译的研究历史却表明,机器翻译的困难程度和复杂程度远远超出了最初倡导机器翻译研究的先驱者们的想象。机器翻译至今仍是一项十分具有挑战性的研究课题。其进展不仅需要计算手段的创新,更要依赖于人们对语言本质以及语言计算模型认识的进展。可以说,语言学研究的水平对机器翻译系统研制的成败起着十分关键的作用。出于这样的认识,本文将讨论机器翻译对语言研究的要求,希望吸引更多语言学研究者将机器翻译作为思考语言学问题的一个参照系,使更多的语言研究成果可以为机器翻译提供帮助。 机器翻译系统的研制工作从20世纪40年代末开始,至今已经发展出许多不同的方法。总体来看,现有的机器翻译方法可以归纳为三种类型:一种是基于规则(rule-based)的方法;第二种是基于统计(statistic-based)的方法;第三种是基于实例(example-based)的方法。限于篇幅,这里我们主要介绍第一种方法的工作模式。 基于规则的机器翻译方法把翻译过程看作是一个在语言学知识引导下的符号变换过程。这种方法要求把有关源语言和目标语言的知识以计算机可以操作(“看懂”)的形式表示出来。下面以汉英机器翻译为例说明翻译的基本过程。 1.1 源语言的词法分析 这一阶段利用源语言词汇层面的知识,识别出源语言文本字符串中的单词,并从词典中获得每个单词的句法语义知识,以备在后续处理中使用。 例如汉语句子“她把一束花放在桌上”,经过词法分析,会得到下面的结果:(注:斜杠后字母是词性标记,r表示代词,p介词,m数词,q量词,n名词,ng名词性语素,f方位词,w标点符号(下文所用标记符号含义同此)。) 她/r 把/p 一/m 束/q 花/n 放/v 在/p 桌/ng 上/f 。/w 1.2 源语言词串的句法分析 为得到句法结构以及跟结构相关的特征结构(feature structure),这一阶段的处理需要运用句法层面的知识,通常表示为扩展的上下文无关规则(本文第2节有更多的说明),由两个部分组成,一个部分是上下文无关规则(Context Free Rule),指明了短语的组成关系,例如:一个名词短语可以由一个数量结构和另外一个名词短语组成,这个事实用上下文无关规则可以描述为:np→mp np。另外一个部分是一组“合一等式”(unification formula),主要描写在什么条件下可以用这条规则进行组合以及组合之后得到的新的语言单位的属性信息(詹卫东2000)。句法分析的结果可以表示为一棵句法树。 例如我们对上文所述的汉语句子进行句法分析,将会得到图1所示的句法树(注:树形图(包括下面的图2、3)中汉语短语标记以小写字母表示,英语短语标记以大写字母表示。zj表示整句,dj小句,np名词性短语,vp动词性短语,pp介词性短语,mp数词性短语,sp处所词性短语,SS英语的整句,CS小句,其他大写标记含义与小写标记相同。W是标点。)(这里略去了特征结构信息)。
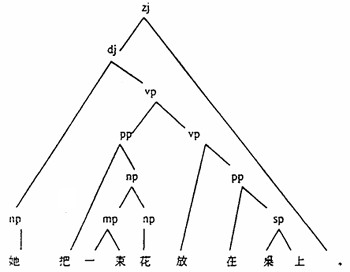
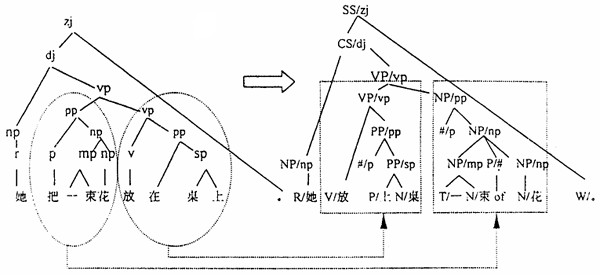
图1 1.3 源语言到目标语言的句法结构转换 结构转换主要利用源语言结构和目标语言结构之间的对应关系进行,通过一组转换规则的指导把源语言的句法树转换成目标语言的句法树。转换规则列出了源语言的句法结构以及对应的目标语言结构,并描述了这种转换关系成立的条件,对于上述例子,图2描述了这种结构转换前后的对应关系,图中右部是转换后得到英语结构树,其中每个树结点都标有两个以斜线分隔的范畴标记,斜线左边的范畴是由斜线右边的范畴转换得到的。