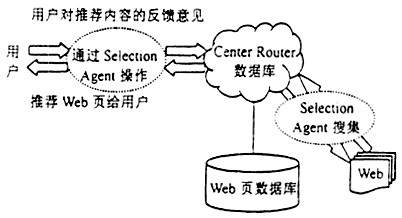
利用数字资源开展有效的信息服务是数字图书馆建设的关键。目前,图书馆数字资源主要包括数据库资源和网络资源两大部分。数据库资源种类多样,但数据交叉重复,内容组织程度不高,信息空间各自独立,查询方式有限,影响用户对信息的选择与获取。而网络资源具有信息量庞大、内容繁杂,数据对象异构、异质等特征,使之无法有效地进行组织和检索。 从数字资源的获取来看,不同的数字资源系统均存在以下问题:仅提供数据的简单查询,不能自动跟踪信息内容的变化;不能根据用户的兴趣需求来定制检索结果,只要关键词相同,给出的查询结果就相同,并不考虑用户的信息偏好。事实上,每个用户感兴趣的主题是不一样的。即使同一用户,在不同的时期其需求也有所侧重。 随着用户对信息的个性化需求日趋凸显,数字图书馆的建设不能仅考虑购置各类数据库,组织众多的网络资源,被动地等待用户前来选择,而应以用户为中心,整合数字资源,提供主动的个性比信息服务。构建一个融多种技术为一体的个性化信息推荐系统[1-4],实现数字资源深层挖掘,是数字图书馆实现个性化信息服务的有效手段。 1 推荐系统的技术基础 推荐系统这一词语首次在文献[4]中被提出,它是一种在特定类型的数据库中进行知识发现的应用技术,使用多种数据分析技术为用户更好的服务,向用户主动、及时、准确地提供所需信息,并能根据用户对推荐内容的反馈进一步改进推荐结果。 目前,用于解决数字资源获取不便的技术主要有3类:信息检索、信息过滤、协同过滤技术,这些技术都可以融入到推荐系统中,但又各有侧重。 1.1 信息检索 信息检索是响应用户提交的搜索请求,返回相应查询结果的信息技术,返回的查询结果大多数根据查询匹配的相似度的高低进行排序后对外发布。一般网络搜索引擎如Yahoo、Alta Vista等均是流行的信息检索系统。信息检索系统一般对文本内容建立全文索引或摘要索引,对非文本内容如图片、视频等则根据一些特征进行索引。信息检索系统容易实现,检索速度快,但其不足在于:①提交一个查询往往返回数以千计的结果,有些是相关的,但大多数并不相关,用户需花费大量时间和精力去作选择;②只能回答用户询问的问题,不能主动、增量地向用户提供知识。 1.2 信息过滤 信息过滤也称为基于内容过滤。它根据用户描述的兴趣特征或跟踪用户的网上行为对用户兴趣建模,获取用户感兴趣的内容项,应用于不同领域的智能Agent系统就是典型的信息过滤系统。由于信息过滤系统加入了用户的个人信息,相对于信息检索的通用性来讲,信息过滤是一种重要的、有效的个性化技术[2,5,6]。信息过滤的优点是能够根据数据库中用户以往的行为向用户推荐。但它也有局限性,信息过滤技术处理的对象多是文本表达的内容。因为它必须要为对象定义特征向量空间,要推荐的每一项内容都必须能使用具有特征的向量表示,但现实生活中很多项无法自动进行特征抽取,如声音剪辑、图像等,这就增加了使用信息过滤技术进行推荐的难度。 1.3 协同过滤 使用协同过滤技术可以避免信息过滤技术的不足,无需考虑内容是什么形式,通过其他用户对内容项的评价进行推荐。基本思想是根据用户以往对内容项的评价,比较用户间的兴趣相似度,然后根据与特定用户具有相似兴趣的其他用户的观点向该用户推荐[1,3,6~8]。其优点是可以不考虑内容项的特征,任何形式的内容都可以推荐。缺点是:①用户对内容的评价矩阵非常稀疏;②如果从来没有用户对某一项内容加以评价,则一个对象不可能被推荐。 2 几个系统实例 随着个性化成为Web技术领域关注的热点,推荐系统的研究也越来越得到学术界和产业界的重视。目前已经研发了多个推荐系统的原型,并在商业上取得了一定成功。以下分析几个比较典型的系统。 1)Tapestry系统[7]。1992年Goldberg等人首次提出了关于“协同过滤”的描述,并研制了从文集中检索特定文章的Tapestry系统。Tapestry系统允许用户对阅读过的文章发表意见,其他用户不仅可以根据关键字检索文章,还可以根据用户的评注意见决定阅读哪些文章。在Tapestry系统中,设定的前提是每一个用户相互了解,这样用户知道哪些人的评注意见值得参考;Tapestry不是自动地根据用户的兴趣向用户推荐,而是需要用户构造复杂的查询才能得到检索结果。其体系结构如图1所示。
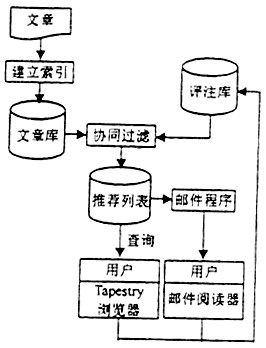
图1 Tapestry体系结构 虽然Tapestry系统相对后来的系统有很多不足之处,但从这时起,关于推荐系统和协同过滤技术的研究已引起广泛注意。 2)Fab系统[2]。Fab是Stanford大学数字图书馆项目的一部分。它的设计思想是,从用户已经评价的文档中抽取一定特征组成用户概况表(User Profile),一个用户具有一个用户概况表,使用TFIDF向量表示。同样地,也使用TFIDF向量来描述文档,计算用户概况信息与文档间的相似度,把与用户概况表内容相似程度高的文档向用户推荐。另外,比较两个用户概况表内容的异同,得到两个用户间的相似度,把和某一用户相似的其他用户的意见向该用户推荐,综合这两种推荐得到对特定用户的推荐结果。Fab体系结构如图2所示。