云南省图书馆机构用户,欢迎您!
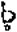 ;同一个“P′”声母,北京话是[P[h]-],南昌话是,太原话是[PX-];同一个“b”声母,上海话是[ph-],宁波话是
;同一个“P′”声母,北京话是[P[h]-],南昌话是,太原话是[PX-];同一个“b”声母,上海话是[ph-],宁波话是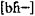 ,松江话是['b-],文昌话是[?b-]。事实上,人们在记音的时候,对没有辨义作用的细微差别是不太在意的;归纳音位,为了突出音位差异,常会对标音符号作一些处理。如上文列举的例子外,还会把
,松江话是['b-],文昌话是[?b-]。事实上,人们在记音的时候,对没有辨义作用的细微差别是不太在意的;归纳音位,为了突出音位差异,常会对标音符号作一些处理。如上文列举的例子外,还会把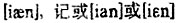 等等。就一个音系来说,只要不出现音位上的混乱,一个音记得严一些,宽一些;开一些,闭一些没有多大的关系,但涉及音系间的比较,就直接关系到是否相同或相异的问题。脱离具体音系直接比较各方言的音值,音值的同一性问题也许是难以克服的障碍。郑先生的统计结果同一般对汉语方言分区的认识有较大的距离,这也许是一个重要的原因。① 本文尝试换一个角度,以古音类为标准,用统计的方法,对汉语各方言的声类、韵类和调类进行全面比较。这个作为标准的古音类以《切韵》音系为基础,但不是说现代汉语方言都是直接从《切韵》音系演变来的,而是把《切韵》音系当作比较的参照系。 1、我们以北京大学中文系语言学教研室编的《汉语方音字汇增订稿》②(下文简称《增订稿》)为基本材料,假设《增订稿》所收的二十个方言点是汉语方言的代表点;《增订稿》所收的常用字可以概括这二十个方言点语音系统的概貌。 1.1《增订稿》所收常用汉字二千九百六十二个,为使比较有据可依,删除了没标明音韵地位的汉字四十七个,实际统计的有效字是二千九百十五个。 《增订稿》一个字有文白两读,北京取文读音,其他地点取白读音;一个字有几读,取第一读音。一字一音,使各方言在统计总量上一致。如:
等等。就一个音系来说,只要不出现音位上的混乱,一个音记得严一些,宽一些;开一些,闭一些没有多大的关系,但涉及音系间的比较,就直接关系到是否相同或相异的问题。脱离具体音系直接比较各方言的音值,音值的同一性问题也许是难以克服的障碍。郑先生的统计结果同一般对汉语方言分区的认识有较大的距离,这也许是一个重要的原因。① 本文尝试换一个角度,以古音类为标准,用统计的方法,对汉语各方言的声类、韵类和调类进行全面比较。这个作为标准的古音类以《切韵》音系为基础,但不是说现代汉语方言都是直接从《切韵》音系演变来的,而是把《切韵》音系当作比较的参照系。 1、我们以北京大学中文系语言学教研室编的《汉语方音字汇增订稿》②(下文简称《增订稿》)为基本材料,假设《增订稿》所收的二十个方言点是汉语方言的代表点;《增订稿》所收的常用字可以概括这二十个方言点语音系统的概貌。 1.1《增订稿》所收常用汉字二千九百六十二个,为使比较有据可依,删除了没标明音韵地位的汉字四十七个,实际统计的有效字是二千九百十五个。 《增订稿》一个字有文白两读,北京取文读音,其他地点取白读音;一个字有几读,取第一读音。一字一音,使各方言在统计总量上一致。如:  “雾”字,长沙有两个读音,取第一读音[mei]。 1.2汉语大多数方言的韵母一般都可以用开齐合撮四呼来归纳。相当多的方言,开口呼零声母字在韵母前往往带有一个喉塞音
“雾”字,长沙有两个读音,取第一读音[mei]。 1.2汉语大多数方言的韵母一般都可以用开齐合撮四呼来归纳。相当多的方言,开口呼零声母字在韵母前往往带有一个喉塞音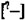 ,齐合撮三呼零声母字在韵母前带有一个摩擦成分,严式标音可以分别记为[ji-]、[wu-/vu-]、[Y-]、由于它们没有辨义作用,一般都处理为零声母。鉴于这种认识,我们对《增订稿》的声母韵母作了一些调整,以便使比较材料尽可能一致。 ①删掉苏州话和温州话的“h”和“j”两个声母。 ②删掉广州话和阳江话的“j”和“W”两个声母③,把[i]、[i-]和[Y]、[Y-]前的“j”直接去掉,把其他元音前的“j”改为介音[i-],把[u]、[u-]前的“W”直接去掉,把其他元音前的“W”改为介音[U-]。 ③删掉太原话和梅县话的“V”声母,把出现在[u]前面的“V”直接去掉,把出现在其他元音前的“V”改为介音[u-]。 1.3辅音独立成音节。根据来源,成音节的辅音来自古声母,就作声母处理,同时在韵母的空位上设立零韵母。成音节的辅音来自古韵母,就作韵母处理,在声母的空位上算有一个零声母。如:
,齐合撮三呼零声母字在韵母前带有一个摩擦成分,严式标音可以分别记为[ji-]、[wu-/vu-]、[Y-]、由于它们没有辨义作用,一般都处理为零声母。鉴于这种认识,我们对《增订稿》的声母韵母作了一些调整,以便使比较材料尽可能一致。 ①删掉苏州话和温州话的“h”和“j”两个声母。 ②删掉广州话和阳江话的“j”和“W”两个声母③,把[i]、[i-]和[Y]、[Y-]前的“j”直接去掉,把其他元音前的“j”改为介音[i-],把[u]、[u-]前的“W”直接去掉,把其他元音前的“W”改为介音[U-]。 ③删掉太原话和梅县话的“V”声母,把出现在[u]前面的“V”直接去掉,把出现在其他元音前的“V”改为介音[u-]。 1.3辅音独立成音节。根据来源,成音节的辅音来自古声母,就作声母处理,同时在韵母的空位上设立零韵母。成音节的辅音来自古韵母,就作韵母处理,在声母的空位上算有一个零声母。如: 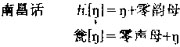 本文把《增订稿》上的二千九百十五个字的每一个都看作是声韵调三者的结合体。 2、古音类的确定。为了避免主观随意性,最好对《切韵》声系的声韵调不作任何更动,以它为标准,直接用于各方言间的比较,但汉语方言的客观现实告诉我们,这样做未必理想。如《切韵》二百零六韵,不算声调平上去的差别,也有九十多个,这些韵在各方言的分合归并,情况极其复杂,用它来比较各方言韵类的异同,势必把一切搞得支离破碎。可见古音类的范围以大为宜。古音类定得大,对统计也有好处。例如我们把声类定为二十二类,韵类定为十九类,调类定为八类,在声韵调的综合统计时,就可以在一定程度上改变以往统计大大压低声母韵母的作用而过分突出声调作用的状况。④当然古音类定得大,可能会掩盖许多细节,不过任何抽象都是以牺牲个别为代价的,我们的目的是划分大方言区,划分大方言区自然不可能顾及各方言的每个细节。
本文把《增订稿》上的二千九百十五个字的每一个都看作是声韵调三者的结合体。 2、古音类的确定。为了避免主观随意性,最好对《切韵》声系的声韵调不作任何更动,以它为标准,直接用于各方言间的比较,但汉语方言的客观现实告诉我们,这样做未必理想。如《切韵》二百零六韵,不算声调平上去的差别,也有九十多个,这些韵在各方言的分合归并,情况极其复杂,用它来比较各方言韵类的异同,势必把一切搞得支离破碎。可见古音类的范围以大为宜。古音类定得大,对统计也有好处。例如我们把声类定为二十二类,韵类定为十九类,调类定为八类,在声韵调的综合统计时,就可以在一定程度上改变以往统计大大压低声母韵母的作用而过分突出声调作用的状况。④当然古音类定得大,可能会掩盖许多细节,不过任何抽象都是以牺牲个别为代价的,我们的目的是划分大方言区,划分大方言区自然不可能顾及各方言的每个细节。