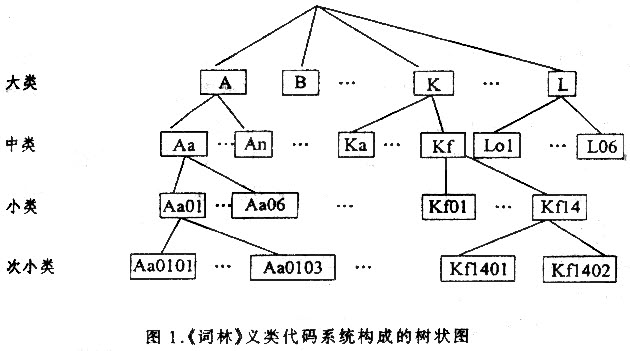
[中图分类号]H085.6[文献标识码]A[文章编号]1003-5397(2000)03-0085-06 词义排歧(word sense disambiguation)指根据一个多义词在文本中出现的上下文环境来确定其词义代码。这个代码既可以是该词义在一部普通词典中的义项号,也可以是它在一部义类词典中的义类代码。长期以来,词义排歧一直被认为是自然语言处理的一个难题。90年代以前,词义排歧研究主要采用人工智能方法,其困难在于要用人工来编制大量的排歧规则,不仅覆盖面很窄,而且开销巨大,即所谓知识获取的“瓶颈”问题。90年代以后,由于大规模机储词典和语料库的出现,词义排歧研究进入了一个以语料库方法为主的新时期。 一种基于词典的词义排歧方法凭借普通词典中词条的释义文本来实现排歧,即计算一个多义词各义项的释义文本与该词所在当前文本的匹配程度,如Lesk和Wilks分别提出的词义排歧方法。[1]但如果词条的释义文本比较短,比如只用近义词或反义词来释义,则在多义词出现的上下文中将很难找到与释义文本重叠的信息,从而影响了词义排歧的效果。另外一类基于词典的词义排歧方法利用义类词典,代表性的工作是Yarowsky提出的词义排歧算法。[3]这种方法由于在计算每个语义类的凸显词(salient words)时将多义词的在语料库中的分布平均分到各个语义类中,从而引入统计噪声;另一方面,由于寻找凸显词所使用的语料范围受限,因而覆盖面较窄。[1][2] 基于语科库的词义排歧方法(Yarowsky 1994,Bruce 1995等)大都需要对训练语料库进行词义的人工标注,这种标注工作既费时又费力,并且统计结果存在严重的数据稀疏问题,因此一部分学者致力于研究无指导的(unsupervised)排歧知识获取方法。但迄今这些方法大都只停留在几个或十几个多义词的小规模实验上。 本文依托《同义词词林》的语义类体系,[4]认为同义词在文本中出现时,与它们前后同现的那些实词在统计意义上是相似的。因此,不难根据任一同义词集中的众多单义词,在一个大规模语料库上自动获取在它们周围同现的所有实词,进而按这些同现实词的词义分辨能力对它们加权,构成这个语义类的一个“分类器”。由于这种分类器可以从一个未经词义标注的大规模语料库上自动获取,所以这是一种代价最小的无指导学习算法。有趣的是,语言学家在编著《词林》时是用他们的直觉/语感来划分同义词集的,而计算机在构造语义类的分类器时凭借的却是词语在大规模语料库中的搭配同现统计,两者的机理完全不同。可是实验表明,两种不同机理所得到的分类结果却高度吻合。本研究的意义在于,提出了语义类的一种形式化表示,以及一种自动构造语义类分类器的算法,为实现真实文本的计算机自动词义标注奠定了基础。 一 《同义词词林》简介 《词林》的编者在确定词的语义分类时,以词义为主,兼顾词类,并充分注意题材的相对集中。这部义类词典把词义分为大、中、小类三级,共得到12个大类、94个中类、1428个小类,小类以下再按同义词词群设立标题词,共含3925个标题词。 《词林》中用第一个大写英文字母作为大类的编号,紧接着用第二个小写英文字母表示中类,义类代码的第三和第四位是两个阿拉伯数字,用来表示小类的编号。小类以下的标题词还可细分为两个层次,各用两位阿拉伯数字表示。例如,词“觉悟”的义类代码为"Ga15",其中大类编码G表示“心理活动”,中类编码Ga表示“心理状态”,小类编码是Ga15,它在《词林》中的内容显示为: Ga15 醒悟 懂事 醒悟 觉悟 省悟 憬悟 觉醒 清醒 醒(猛) 如梦初醒 大梦初醒…… 懂事 记事儿 开窍 通窍 也就是说,Ga15包含两个标题词:“醒悟”和“懂事”,分别代表这一小类以下的两个词群。因此,词“觉悟”的完整义类代码是Ga150101. 《词林》以词的义项为收词单位,多义词按其词义被赋以不同的义类代码。例如,词“材料”在《词林》中有三个义项:(1)可以直接造成成品的东西;(2)提供著作的内容的事物或可供参考的事实;(3)比喻适于做某种事情的人才。它们对应的义类代码分别为"Ba06""Dk17"和"A103"。对“材料”一词的词义排歧过程,就是要根据该词出现的上下文给它标注一个正确的义类代码。 如上所述,《词林》的义类代码系统构成了一幅有层次结构的树状图,如图1所示。
《词林》收入的词条实际上包括了词和部分短语、成语、俗语,总共50154条。《词林》中多义词的分布情况如表1所示。统计表明,《词林》中总共有7430条多义词,占词条总数的14.8%,即七分之一强。值得注意的是,仅占词条总数7.52%的3774条单字词中,却有近一半(即1801条)是多义的;相比之下,在46380条多字词中,只有12.1%是多义的。 表1. 《词林》中多义词的分布情况 单字词多字词词条总数 词条数百分比词条数百分比 单义词 1973 52.3% 40751 87.9% 42724