云南省图书馆机构用户,欢迎您!
本文利用对中西部6省的贫困地区所作的农户调查资料, 根据离散型解释变量模型对农户的非农劳动供给的决定因素进行了系统分析。结合对工资方程的估计结果,揭示了贫困地区农户对非农工作参与的主要动机在于分散收入波动所带来的风险、人力资本变量对于农户形成非农劳动供给决策具有促进作用。
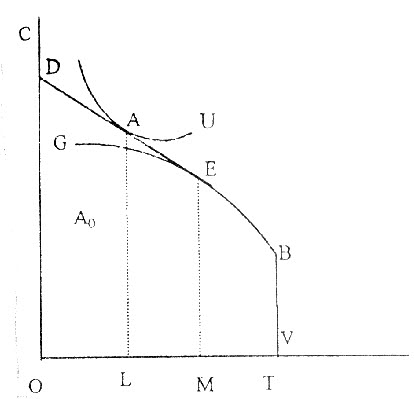 图 农户家庭时间在各用途间的配置 1.2 教育对贫困地区非农劳动供给的影响 如前所述,就农村贫困地区而言,教育对于劳动供给的影响可能在于它能提供给人们认识市场机会的能力。并且由于收入的易波动性,出于规避风险的动机,劳动供给也可能表现出分散化,而教育的另一层作用就可能在于它能减少劳动供给分散化可能带来的效用损失。从经验估计的角度看,如果教育对于发现市场机会有积极影响的话,那么它必将显著地影响对非农工作的参与。而这种参与是出于收入均等化的原因,还是分散风险的动机,则要看教育变量在工资方程中的作用。 2.教育对贫困地区非农工资率的影响 2.1 工资方程的形式 对贫困地区所进行的农户调查发现,由于贫困地区的劳动市场不完全,教育在工资方程中的作用并不显著。一个保留的假设是教育是与其他社会经济环境变量共同发生作用的。 以每天工作8小时为标准工作时间,日工资为标准工资率, 从事非农工作的工资率的对数为被解释变量,我们得到如下形式的工资方程:
图 农户家庭时间在各用途间的配置 1.2 教育对贫困地区非农劳动供给的影响 如前所述,就农村贫困地区而言,教育对于劳动供给的影响可能在于它能提供给人们认识市场机会的能力。并且由于收入的易波动性,出于规避风险的动机,劳动供给也可能表现出分散化,而教育的另一层作用就可能在于它能减少劳动供给分散化可能带来的效用损失。从经验估计的角度看,如果教育对于发现市场机会有积极影响的话,那么它必将显著地影响对非农工作的参与。而这种参与是出于收入均等化的原因,还是分散风险的动机,则要看教育变量在工资方程中的作用。 2.教育对贫困地区非农工资率的影响 2.1 工资方程的形式 对贫困地区所进行的农户调查发现,由于贫困地区的劳动市场不完全,教育在工资方程中的作用并不显著。一个保留的假设是教育是与其他社会经济环境变量共同发生作用的。 以每天工作8小时为标准工作时间,日工资为标准工资率, 从事非农工作的工资率的对数为被解释变量,我们得到如下形式的工资方程: 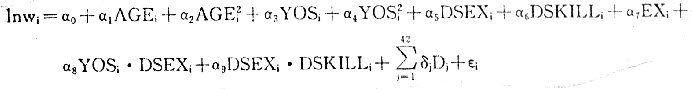 AGE为年龄,YOS为受到正规教育的年限,DSEX为参与者的性别虚拟变量,EX为经验变量,DSKILL为参与者的技能虚拟变量,D 为村虚拟变量。 与一般的工资方程相比,上述方程有这样几个特点: 第一,没有放入经验的平方项。因为,传统的工资方程所使用的经验变量是以年龄减去受教育年限和未成年部分作为替代。在我们使用的数据中,工作经验是根据被调查者的报告年限所得,能直接反映其参与非农工作的经历。 第二,放入教育的平方项,以检验在贫困地区的劳动力市场上是否存在某一个有效的教育水平,能最好地决定其在劳动市场的收益。 第三,工资方程中放入交叉项。如性别与技能的交叉项,教育与性别的交叉项等。 函数形式采取半对数,即工资率采取了对数的形式(后面的模型中工资率也都是对数形式,见表1)。 2.2 样本有偏选择及其调整 正如数据丢失会导致有偏估计一样,在研究过程中对样本进行非随机的选择以估计其行为关系也会导致有偏估计。在实践中,样本有偏选择可能来源于两类原因。第一,被调查的个体可能存在自选择的情况;第二,研究者或数据处理者在其操作过程中采取类似自选择的方式对样本进处理。
AGE为年龄,YOS为受到正规教育的年限,DSEX为参与者的性别虚拟变量,EX为经验变量,DSKILL为参与者的技能虚拟变量,D 为村虚拟变量。 与一般的工资方程相比,上述方程有这样几个特点: 第一,没有放入经验的平方项。因为,传统的工资方程所使用的经验变量是以年龄减去受教育年限和未成年部分作为替代。在我们使用的数据中,工作经验是根据被调查者的报告年限所得,能直接反映其参与非农工作的经历。 第二,放入教育的平方项,以检验在贫困地区的劳动力市场上是否存在某一个有效的教育水平,能最好地决定其在劳动市场的收益。 第三,工资方程中放入交叉项。如性别与技能的交叉项,教育与性别的交叉项等。 函数形式采取半对数,即工资率采取了对数的形式(后面的模型中工资率也都是对数形式,见表1)。 2.2 样本有偏选择及其调整 正如数据丢失会导致有偏估计一样,在研究过程中对样本进行非随机的选择以估计其行为关系也会导致有偏估计。在实践中,样本有偏选择可能来源于两类原因。第一,被调查的个体可能存在自选择的情况;第二,研究者或数据处理者在其操作过程中采取类似自选择的方式对样本进处理。