云南省图书馆机构用户,欢迎您!
不同方言词项的语音音类(声韵调)根据已经确定的语音对应规律而具有同源或非同源的属性,如果用代码1/0标记同源或非同源音类,就得到用以进行相关分析的变量数据。本文根据苗瑶语方言之间音类相关系数的聚类分析,得到从每一个方言自成一类到所有方言只分两大簇群之间任何一个层次上的分类,目的是探讨利用方言的数量分布特征进行亲疏程度和系属分类的计量研究方法。
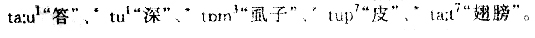 运用手工的方法得出这样的结果是相当费工夫的。如果用程序来自动实现同样的比较工作,得到同样的比较结果要容易得多,并且还可以免去以下人为手工操作的烦琐工作: 表1.1 苗瑶语同源词例表
运用手工的方法得出这样的结果是相当费工夫的。如果用程序来自动实现同样的比较工作,得到同样的比较结果要容易得多,并且还可以免去以下人为手工操作的烦琐工作: 表1.1 苗瑶语同源词例表 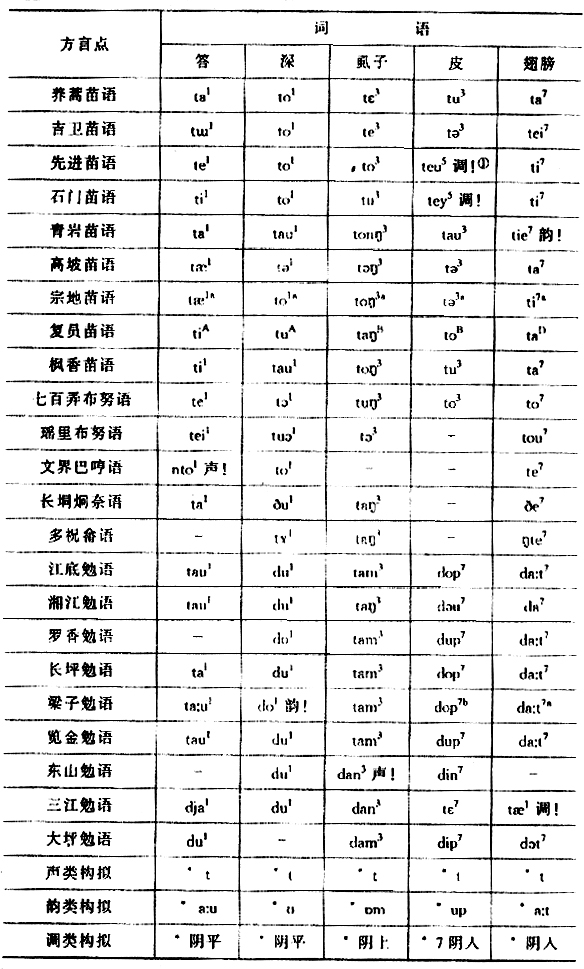 (注:“!”表示该词在这个方言点的声母、韵母或声调不符合语音对应规律。) 1.人为地选词。王、毛所列举的800多同源词, 是经过多年手工识别从数千词中挑选出来的。而计量比较研究可以直接从任何已给定的词库中自动识别同源信息和非同源信息,从而比较可靠地确定同源词。 2.人为地规定对应规律的数量标准。手工比较硬性规定两个以上词的对应可以成立,两个以下为孤证,显得比较勉强。计量比较研究对应规律的概念是建立在概率的基础之上的,充分地利用了词语同源特征和非同源特征数量分布的差异。 3.人为地构拟古音的音值。我们认为这种做法是没有意义的,简单地靠诸多现行方言的语音一般不可能叠加为共同的古音,因为语音的古今演变是一种非线性的动态过程。 苗瑶语的计量比较研究基于以下主要原则: 1.计量比较研究虽然仍是从语言方言系属关系和系属分类的定性目的出发,并试图得到相应的结论,但是研究的基础是建立在语言系属特征概率分布的观念上的。即亲属语言或方言由于具有共同的来源,因此这些语言的词因同源的缘故而在形式和意义上应具有某种规则的、有序的对应关系;但是由于语言演变过程中各种难于把握的随机因素的干扰作用,这种规则性并非表现为非此即彼的逻辑关系,而是非等概率的统计学关系。因此定量研究方法之于表现为概率现象的语言系属问题研究显然是必要的。 2.尽管我们强调了语言演变的随机性所引起的概率现象而必须通过定量或统计的方法来研究语言的系属问题,但是同时也不能忽略语言定性特征的重要性。因为对应规律发生在性质相同或相近的语言单位之间的可能性往往要高于性质相异的单位之间,所以假定定性特征有助于判断语言对应规律也是必要的。所谓定性特征是指语言相同或相异的构成特征,例如语音单位相同或相异的发音部位特征或发音方法特征。 3.当测定某语言单位的概率分布值时,需要区分该单位自身在文本中固有的出现概率和因系属关系造成的出现概率。前者对断定对应关系有干扰作用,因此必须通过加权处理来抵消干扰,从而突出系属关系作用,否则会因单位分布的不平衡而使系属关系被遮掩。 二 苗瑶语方言亲疏关系的相关分析 语音对应规律反映的是语言(方言)之间定性的同源关系,然而,它们的同源程度却不能用定性的方法,甚至不能用简单的定量方法(如统计同源词的百分比)确定。所谓亲疏关系指的就是语言(方言)之间的联系(亲)和差别(疏)关系,由于语言计量研究运用相关、聚类分析等比较复杂的统计方法,因此可以深入地揭示方言的亲疏关系,并且可以做到比较科学的系属分类。 相关分析是反映变量之间相关程度的描述统计方法。 设不同方言为不同的变量,每个方言变量都有一组词义相同的词项,不同方言词项的语音音类(声韵调)根据已经确定的语音对应规律(注:通过计量方法建立方言之间语音对应规律的方法将另文讨论。)而具有同源或非同源(即符合对应规律的同源,不符合对应规律的不同源)的属性,如果用代码1/0标记同源或非同源音类,就得到用以进行相关分析的变量数据。
(注:“!”表示该词在这个方言点的声母、韵母或声调不符合语音对应规律。) 1.人为地选词。王、毛所列举的800多同源词, 是经过多年手工识别从数千词中挑选出来的。而计量比较研究可以直接从任何已给定的词库中自动识别同源信息和非同源信息,从而比较可靠地确定同源词。 2.人为地规定对应规律的数量标准。手工比较硬性规定两个以上词的对应可以成立,两个以下为孤证,显得比较勉强。计量比较研究对应规律的概念是建立在概率的基础之上的,充分地利用了词语同源特征和非同源特征数量分布的差异。 3.人为地构拟古音的音值。我们认为这种做法是没有意义的,简单地靠诸多现行方言的语音一般不可能叠加为共同的古音,因为语音的古今演变是一种非线性的动态过程。 苗瑶语的计量比较研究基于以下主要原则: 1.计量比较研究虽然仍是从语言方言系属关系和系属分类的定性目的出发,并试图得到相应的结论,但是研究的基础是建立在语言系属特征概率分布的观念上的。即亲属语言或方言由于具有共同的来源,因此这些语言的词因同源的缘故而在形式和意义上应具有某种规则的、有序的对应关系;但是由于语言演变过程中各种难于把握的随机因素的干扰作用,这种规则性并非表现为非此即彼的逻辑关系,而是非等概率的统计学关系。因此定量研究方法之于表现为概率现象的语言系属问题研究显然是必要的。 2.尽管我们强调了语言演变的随机性所引起的概率现象而必须通过定量或统计的方法来研究语言的系属问题,但是同时也不能忽略语言定性特征的重要性。因为对应规律发生在性质相同或相近的语言单位之间的可能性往往要高于性质相异的单位之间,所以假定定性特征有助于判断语言对应规律也是必要的。所谓定性特征是指语言相同或相异的构成特征,例如语音单位相同或相异的发音部位特征或发音方法特征。 3.当测定某语言单位的概率分布值时,需要区分该单位自身在文本中固有的出现概率和因系属关系造成的出现概率。前者对断定对应关系有干扰作用,因此必须通过加权处理来抵消干扰,从而突出系属关系作用,否则会因单位分布的不平衡而使系属关系被遮掩。 二 苗瑶语方言亲疏关系的相关分析 语音对应规律反映的是语言(方言)之间定性的同源关系,然而,它们的同源程度却不能用定性的方法,甚至不能用简单的定量方法(如统计同源词的百分比)确定。所谓亲疏关系指的就是语言(方言)之间的联系(亲)和差别(疏)关系,由于语言计量研究运用相关、聚类分析等比较复杂的统计方法,因此可以深入地揭示方言的亲疏关系,并且可以做到比较科学的系属分类。 相关分析是反映变量之间相关程度的描述统计方法。 设不同方言为不同的变量,每个方言变量都有一组词义相同的词项,不同方言词项的语音音类(声韵调)根据已经确定的语音对应规律(注:通过计量方法建立方言之间语音对应规律的方法将另文讨论。)而具有同源或非同源(即符合对应规律的同源,不符合对应规律的不同源)的属性,如果用代码1/0标记同源或非同源音类,就得到用以进行相关分析的变量数据。