云南省图书馆机构用户,欢迎您!
面对智能技术发展的机遇与挑战,世界一流大学通过建设计算社会科学实验室推动文科知识生产创新。基于扎根理论分析全球26个高校计算社会科学实验室发现,情境驱动、创新网络、知识集群与评估问责组成了数字时代文科知识生产的整体框架,分别承担目标导向、算力支持、数字协作与质量控制功能。四者间的互动共同构建了数字化的文科知识生产运行机制,也促成了文科知识生产创新生态系统,使“大学-政府-行业-公民社会”知识共同体有机联结并具备更大的创新协调能力。为此,大学亟须科学制定文科实验室建设规划方案,建立开放共享的数字协作系统,完善智能设施和技术结构以及健全成果评价体系和伦理标准,从而促进文科知识生产的数字化转型。
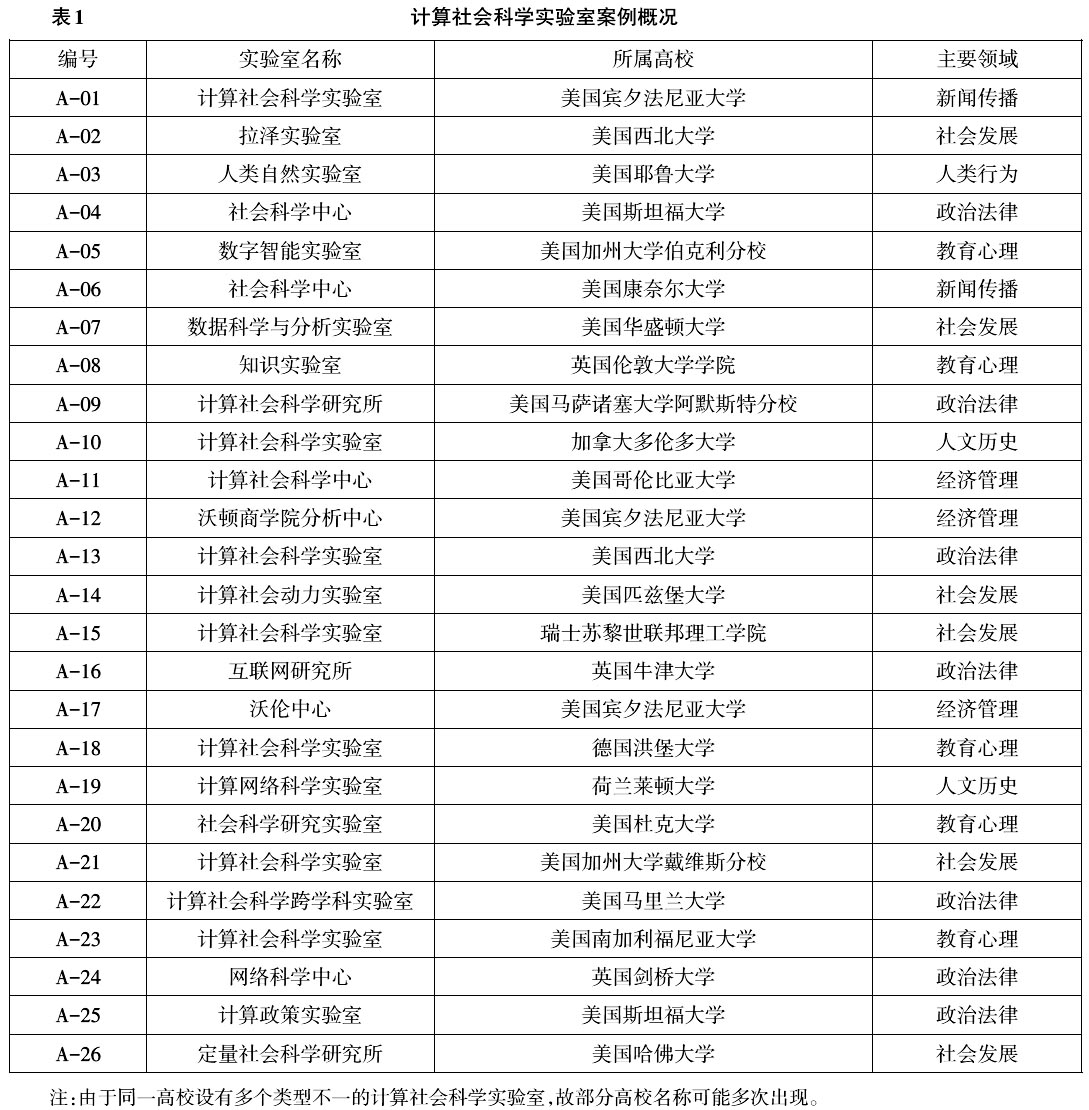 二、研究设计 (一)理论抽样与研究方法 在案例选择方面,本研究通过多渠道收集了78个世界一流大学计算社会科学实验室素材,从而形成分析该问题的初步案例资料库。为了更加精准地匹配适切案例进入分析,对备选案例库进行了理论抽样。抽样原则体现在四个方面:一是所选实验室在人文社会科学领域具有代表性,其所属高校为全球排名前列的精英高校;二是所选机构与数据平台、政府、社会建立了长期合作;三是机构类型尽可能地涵盖人文社会科学诸领域;四是所选案例资料至少由网站信息、学术论文、媒体资料三种以上分析文本组成,且字数不低于0.8万字。基于上述原则,最终遴选了26个案例作为研究样本。 研究采用扎根理论方法并基于Nvivo 12.0软件从26个实验室案例样本中随机抽取18个案例,对所涉案例的相关资料采取开放式编码、主轴编码与选择性编码,并分类、提炼与概括数字时代计算社会科学实验室知识生产的关键信息,据此建立与研究问题相契合的分析框架。然后,利用剩余的8个案例资料进行饱和度检验,从而确定得出最后的研究模型。 (二)资料收集 为了系统呈现26个计算社会科学实验室的样本信息,本研究列举了所选案例概况(详见表1)。为了最大限度地还原各实验室的知识生产过程,本研究从实验室官网、学术论文、研究报告与媒体宣传四个方面收集了各案例的文字、视频与图片信息,并将其全部转换为统一的文本信息,按照抽样编码原则进行归类编号,以此作为后续分析的数据资料支撑。 三、资料编码分析 在组织社会学语境下,机制是指组织内部各要素之间的结构关系及其运作方式,而运行机制是指影响组织活动的因素、结构、功能及其相互关系,以及诸因素所产生影响的作用过程与运作方式。[6]因此,本研究基于扎根理论旨在挖掘计算社会科学实验室知识生产过程的核心要素及其诸要素相互作用机制,以此刻画数字时代文科知识生产的运行过程。 (一)概念与范畴化 开放式编码是基于研究的问题情境对原始素材进行提炼与概括,进而形成初始概念及其范畴化的过程。为此,本研究根据随机原则抽取18个正式样本,除A-05、A-09、A-12、A-14、A-18、A-19、A-21与A-24未入选外,其余案例进入分析阶段。随后,将入选案例材料导入Nvivo12软件中进行编码,经过反复比对、归纳与整合,最终提炼出43个初始概念,并进一步归纳为包含应用服务、项目治理、数字协作与外部问责在内的13个初始范畴。(详见表2)
二、研究设计 (一)理论抽样与研究方法 在案例选择方面,本研究通过多渠道收集了78个世界一流大学计算社会科学实验室素材,从而形成分析该问题的初步案例资料库。为了更加精准地匹配适切案例进入分析,对备选案例库进行了理论抽样。抽样原则体现在四个方面:一是所选实验室在人文社会科学领域具有代表性,其所属高校为全球排名前列的精英高校;二是所选机构与数据平台、政府、社会建立了长期合作;三是机构类型尽可能地涵盖人文社会科学诸领域;四是所选案例资料至少由网站信息、学术论文、媒体资料三种以上分析文本组成,且字数不低于0.8万字。基于上述原则,最终遴选了26个案例作为研究样本。 研究采用扎根理论方法并基于Nvivo 12.0软件从26个实验室案例样本中随机抽取18个案例,对所涉案例的相关资料采取开放式编码、主轴编码与选择性编码,并分类、提炼与概括数字时代计算社会科学实验室知识生产的关键信息,据此建立与研究问题相契合的分析框架。然后,利用剩余的8个案例资料进行饱和度检验,从而确定得出最后的研究模型。 (二)资料收集 为了系统呈现26个计算社会科学实验室的样本信息,本研究列举了所选案例概况(详见表1)。为了最大限度地还原各实验室的知识生产过程,本研究从实验室官网、学术论文、研究报告与媒体宣传四个方面收集了各案例的文字、视频与图片信息,并将其全部转换为统一的文本信息,按照抽样编码原则进行归类编号,以此作为后续分析的数据资料支撑。 三、资料编码分析 在组织社会学语境下,机制是指组织内部各要素之间的结构关系及其运作方式,而运行机制是指影响组织活动的因素、结构、功能及其相互关系,以及诸因素所产生影响的作用过程与运作方式。[6]因此,本研究基于扎根理论旨在挖掘计算社会科学实验室知识生产过程的核心要素及其诸要素相互作用机制,以此刻画数字时代文科知识生产的运行过程。 (一)概念与范畴化 开放式编码是基于研究的问题情境对原始素材进行提炼与概括,进而形成初始概念及其范畴化的过程。为此,本研究根据随机原则抽取18个正式样本,除A-05、A-09、A-12、A-14、A-18、A-19、A-21与A-24未入选外,其余案例进入分析阶段。随后,将入选案例材料导入Nvivo12软件中进行编码,经过反复比对、归纳与整合,最终提炼出43个初始概念,并进一步归纳为包含应用服务、项目治理、数字协作与外部问责在内的13个初始范畴。(详见表2)
